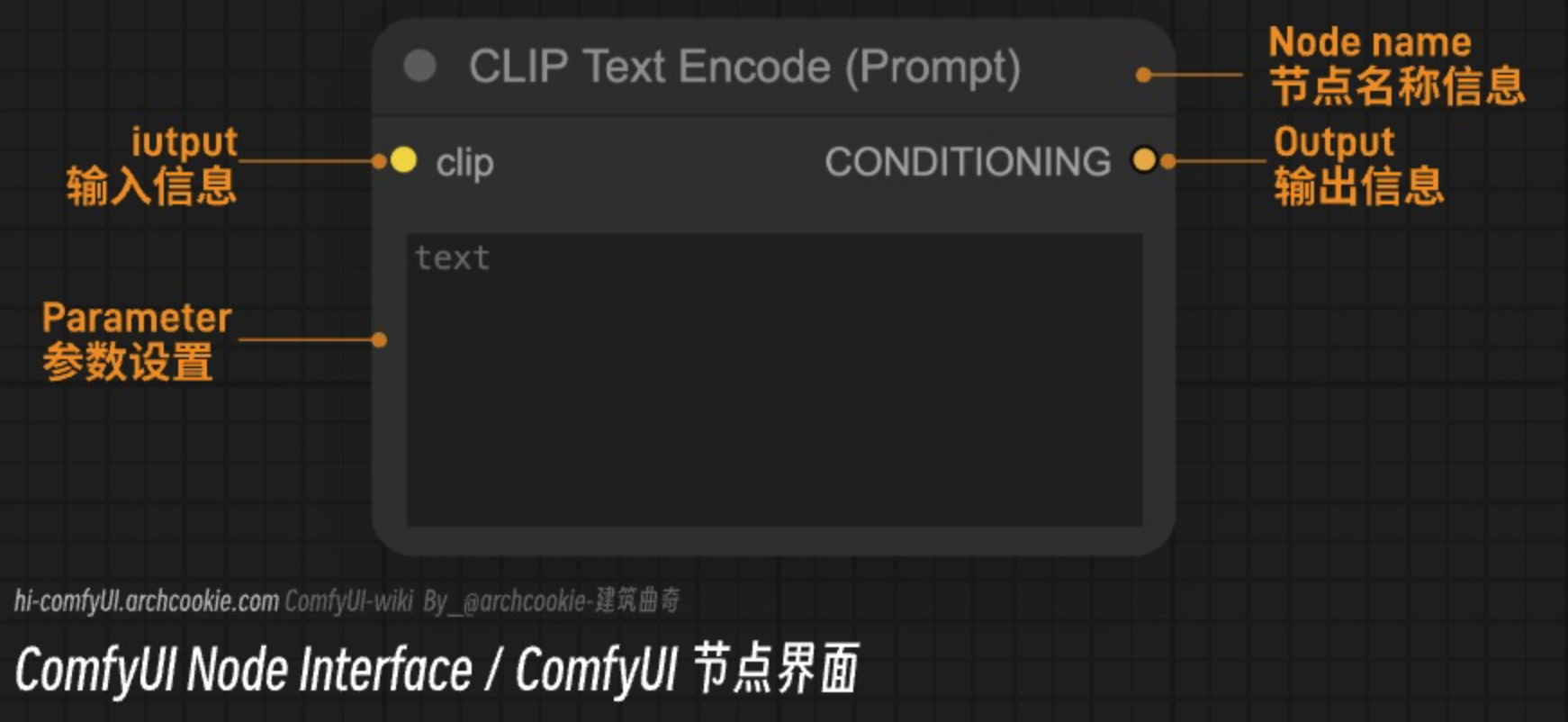
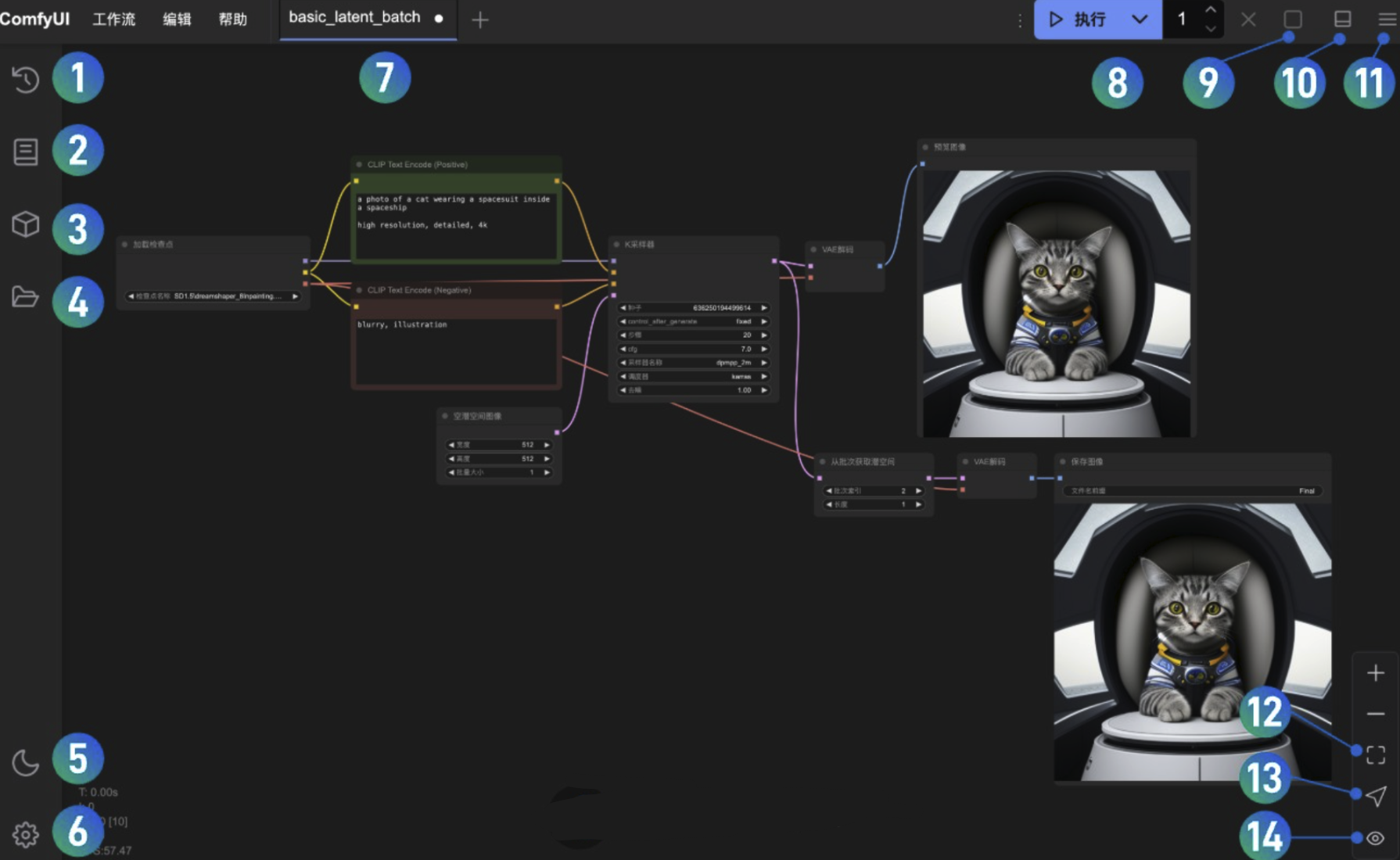
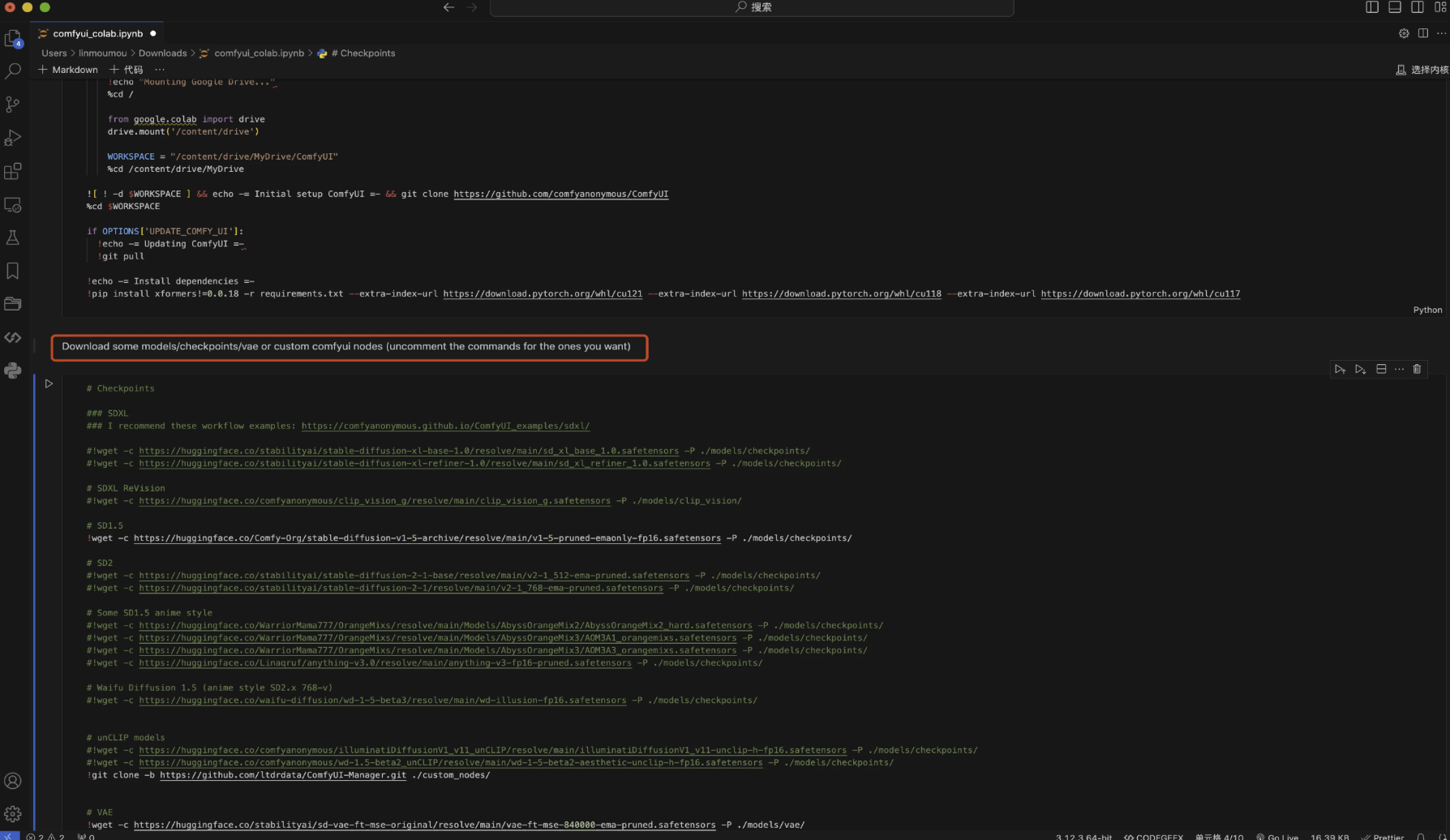
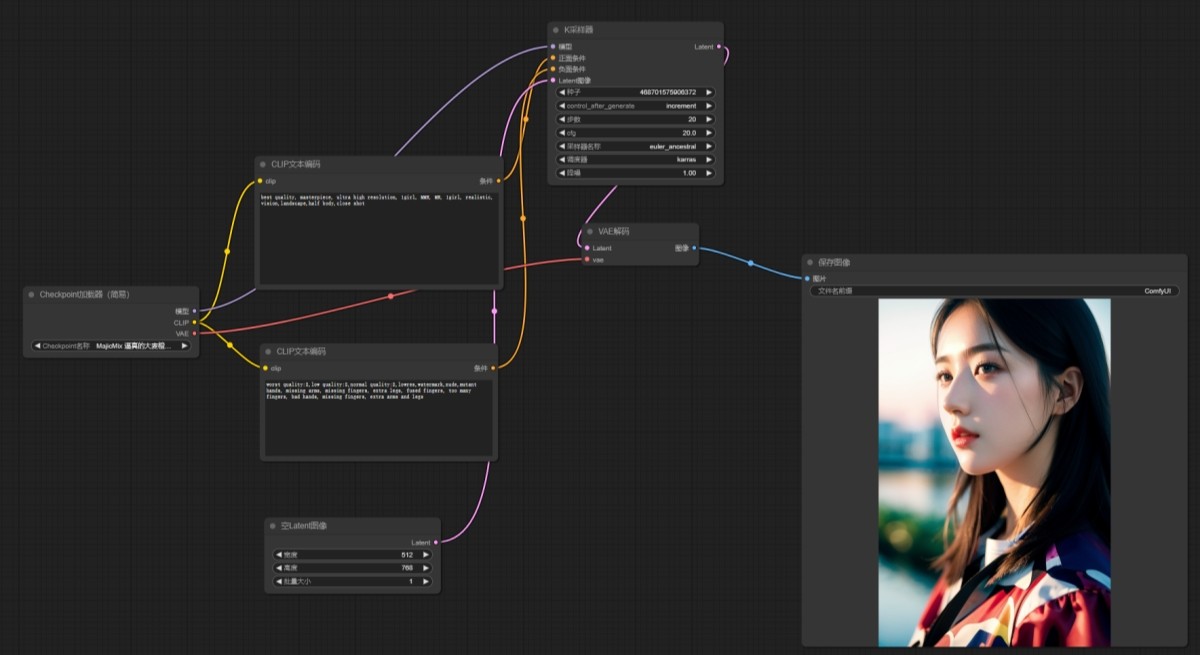
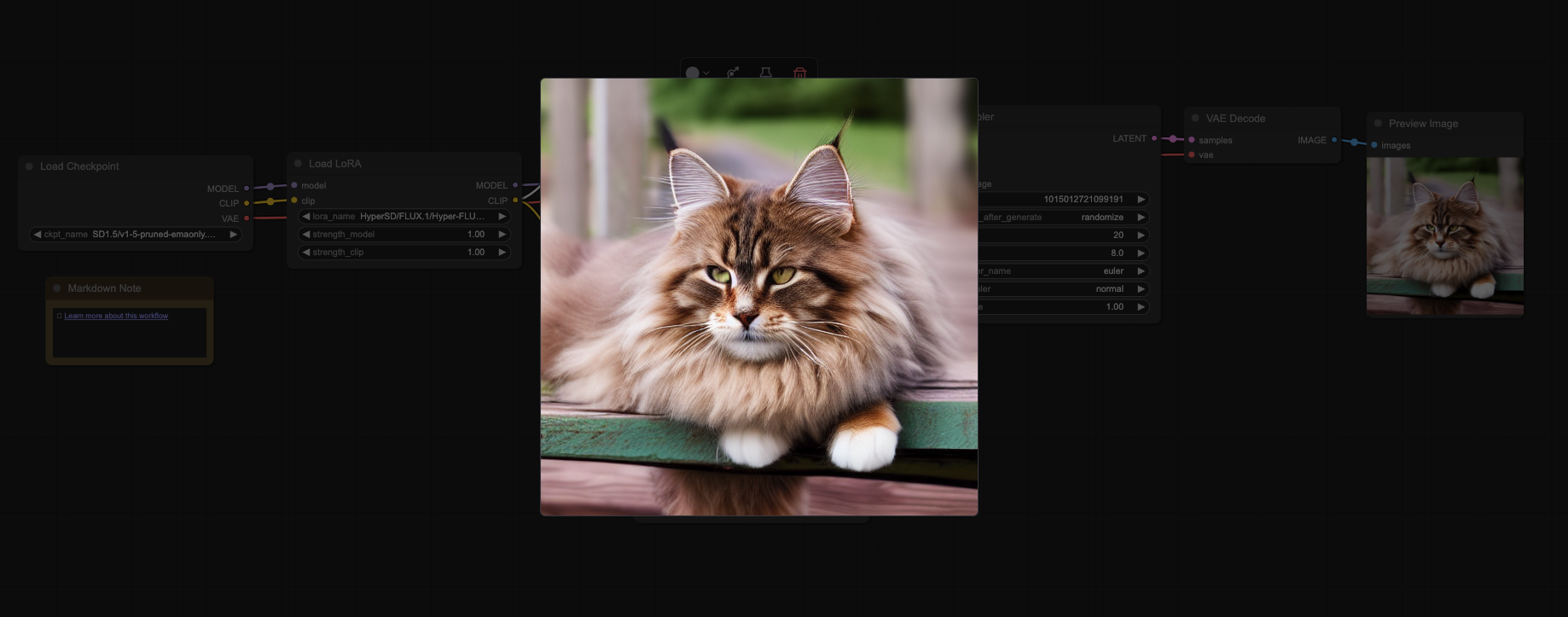
ComfyUI node interface function description
1016
English
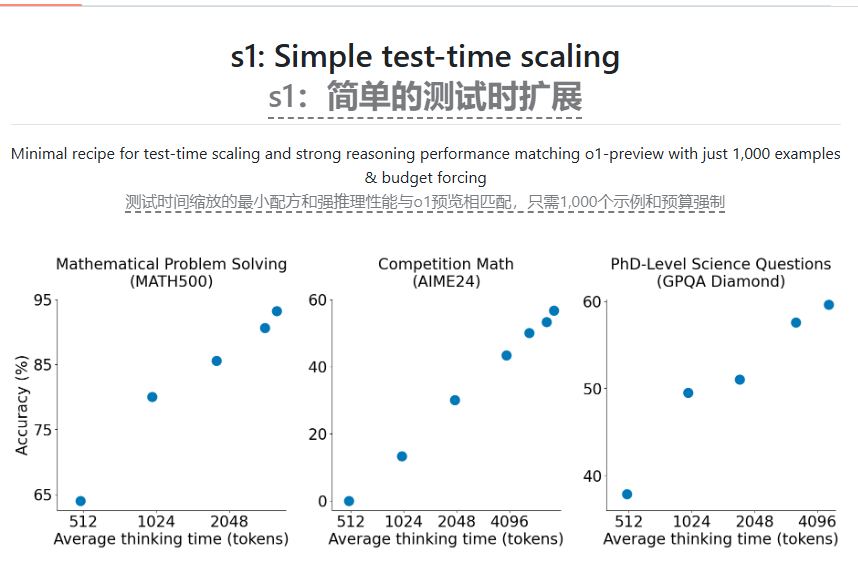
Recently, AI researchers from Stanford University and the University of Washington have successfully trained an AI inference model called s1. The training cost is less than $50 and the required cloud computing credit limit is also very low. The research results were released last Friday, showing that s1 performs no worse than OpenAI's o1 model and DeepSeek's R1 model in mathematical and programming ability testing. The code and data of s1 have been published on GitHub for other researchers to use.
The research team said they started from a ready-made basic model and fine-tuned through distillation to extract the required reasoning capabilities. The distillation process of s1 uses Google's Gemini2.0 Flash Thinking Experimental model, a similar approach to what UC Berkeley researchers used to train another AI inference model last month, which costs about 450 Dollar.
This achievement has inspired many people, especially in today's AI field where researchers can innovate without huge financial support. However, the emergence of s1 also triggered deep thoughts on the commercialization of AI models. If anyone can replicate a multi-million dollar model at a relatively low cost, where is the moat for these big companies?
Obviously, the large AI labs are not satisfied with this, and OpenAI has accused DeepSeek of improperly using its API data for model distillation. The s1 research team hopes to find an easy way to achieve powerful inference performance while improving the ability to "test time expansion" that allows AI models to have more time to think before answering questions. These are the breakthroughs made by OpenAI's o1 model, and DeepSeek and other AI labs have also tried to replicate them in different ways.
s1's research shows that using a relatively small dataset, supervised fine-tuning (SFT) method can effectively distillate inference models, which are often cheaper than the large-scale reinforcement learning method adopted by DeepSeek. Google also provides free access to Gemini2.0Flash Thinking Experimental, but the platform has daily usage restrictions and its terms prohibit reverse engineering its models to develop competitive services.
To train S1, the researchers constructed a dataset of 1,000 carefully selected questions and their corresponding answers, with the "thinking" process behind the questions. The training process used 16 Nvidia H100GPUs, which took less than 30 minutes. According to the researchers, they can now rent the required computing resources for only about $20. In addition, the research team also used a clever technique to let s1 add the word "wait" when reasoning, thereby improving the accuracy of the answer.
In the next 2025, Meta, Google and Microsoft plan to invest hundreds of billions of dollars in AI infrastructure, with some of the funds going to train next-generation AI models. Although distillation has shown good results in the ability to reproduce AI models at a lower cost, it has not significantly improved the performance of new AI models.
Paper: https://arxiv.org/pdf/2501.19393
Code: https://github.com/simplescaling/s1