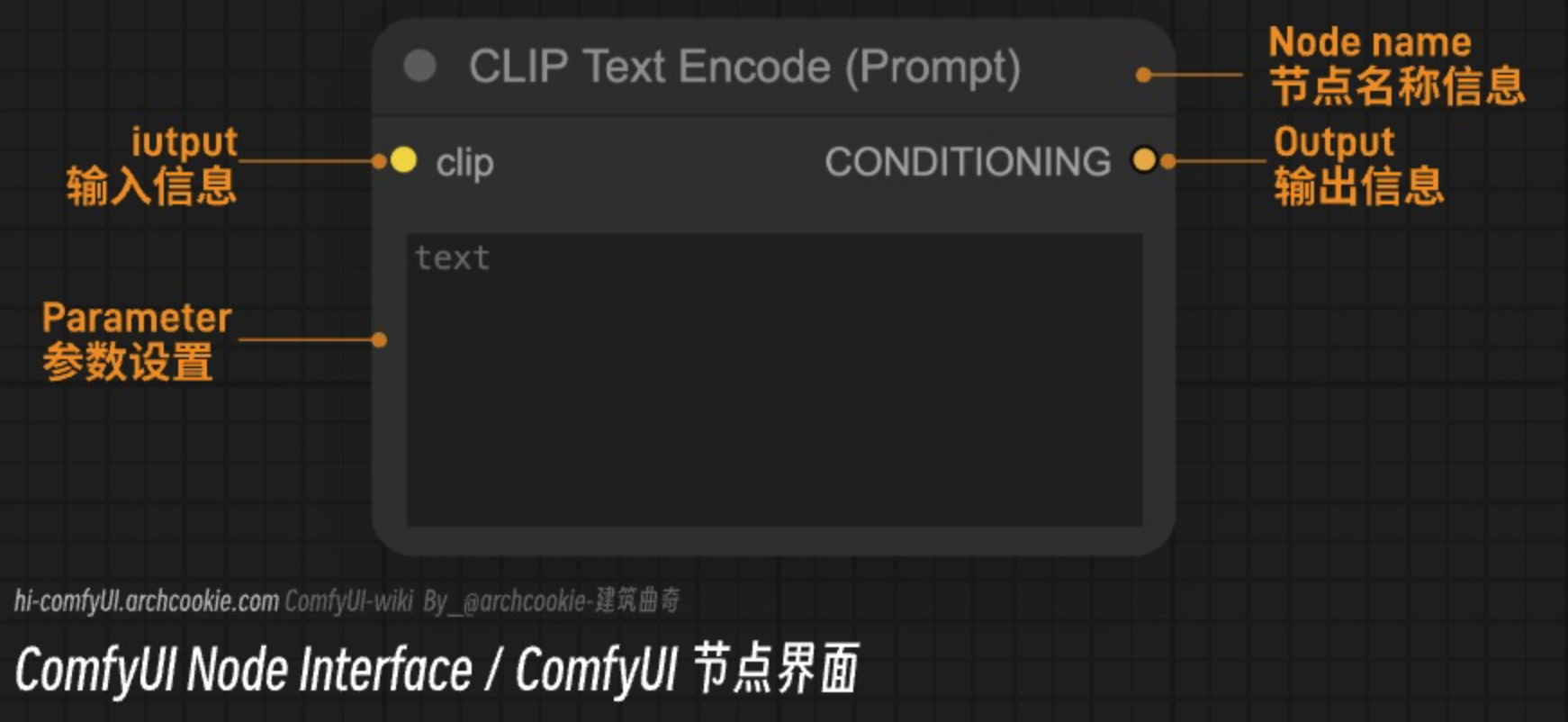
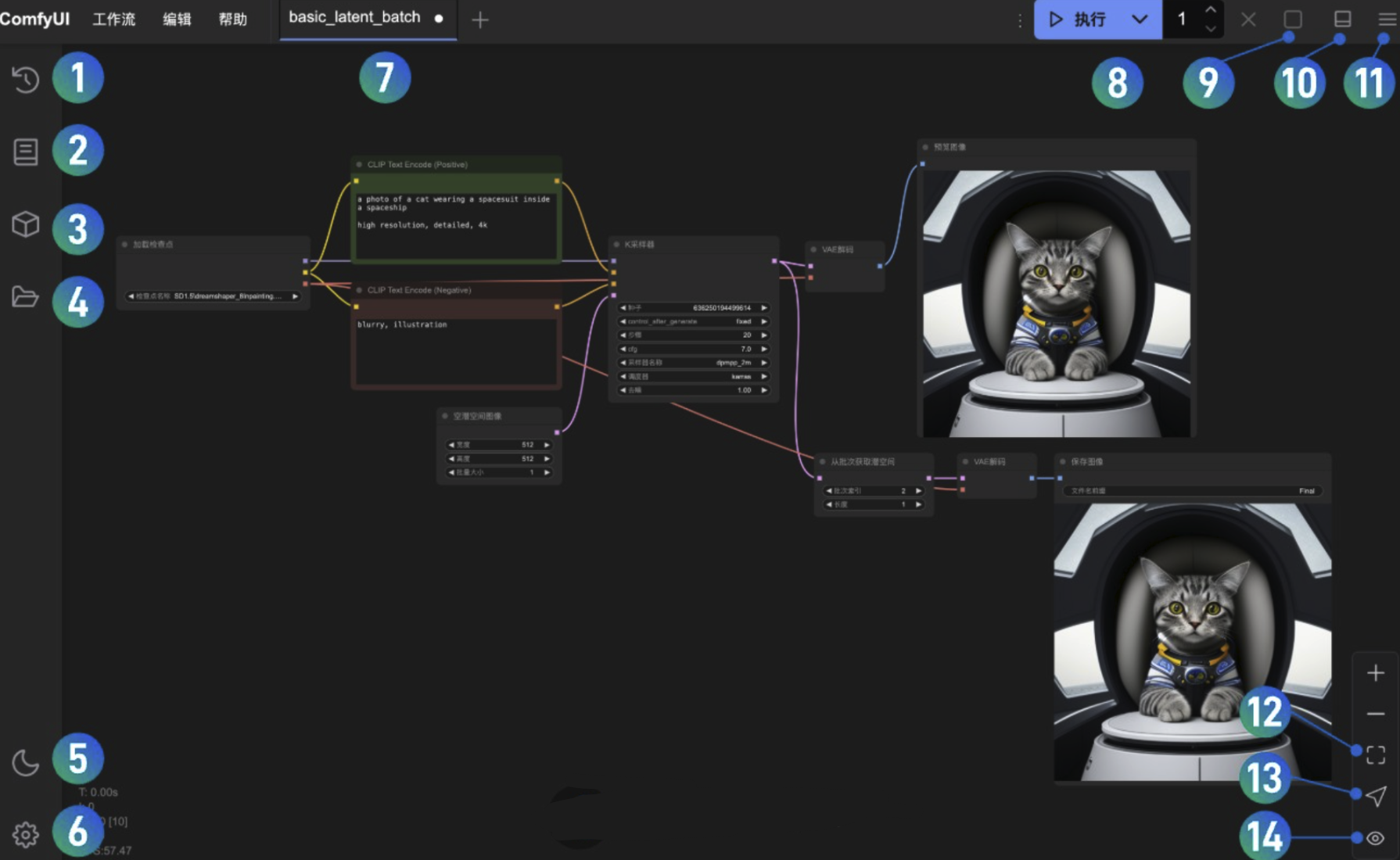
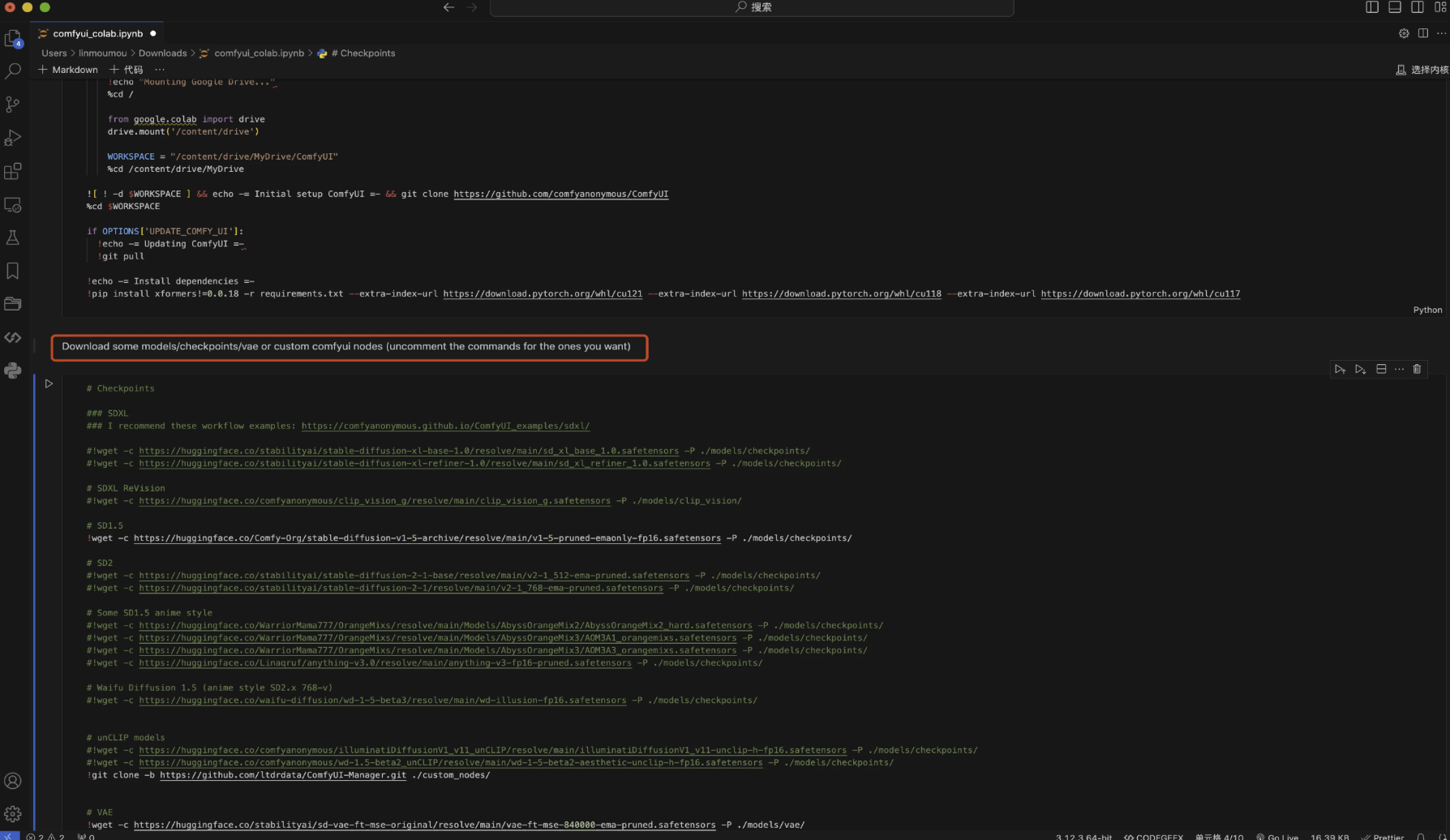
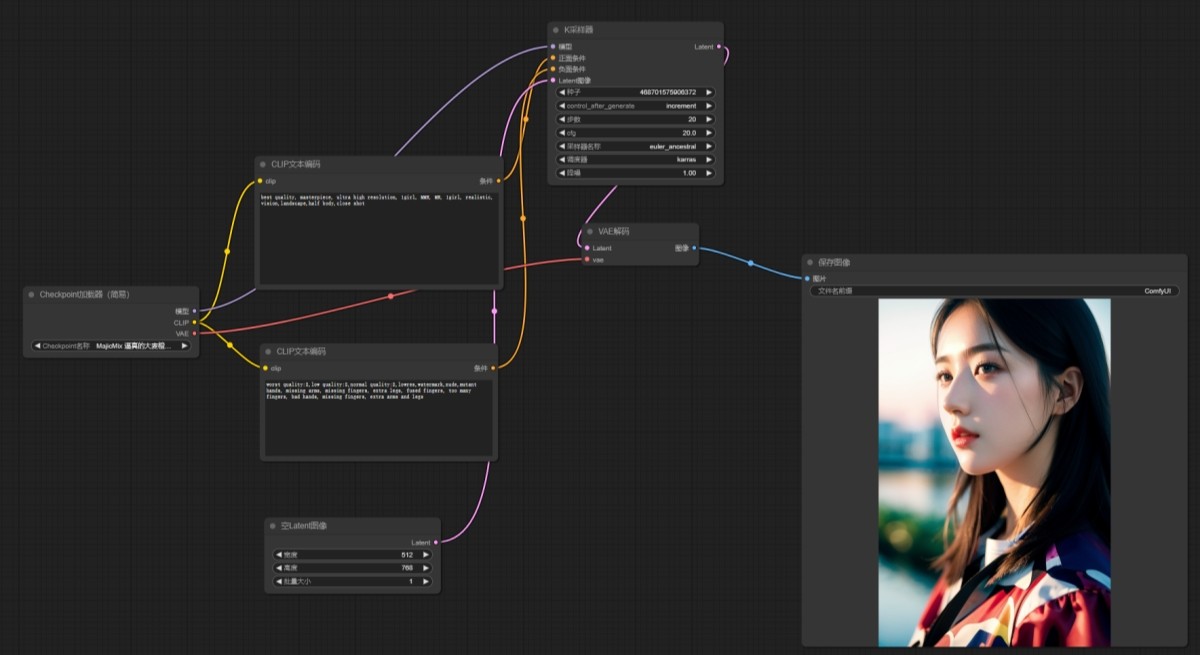
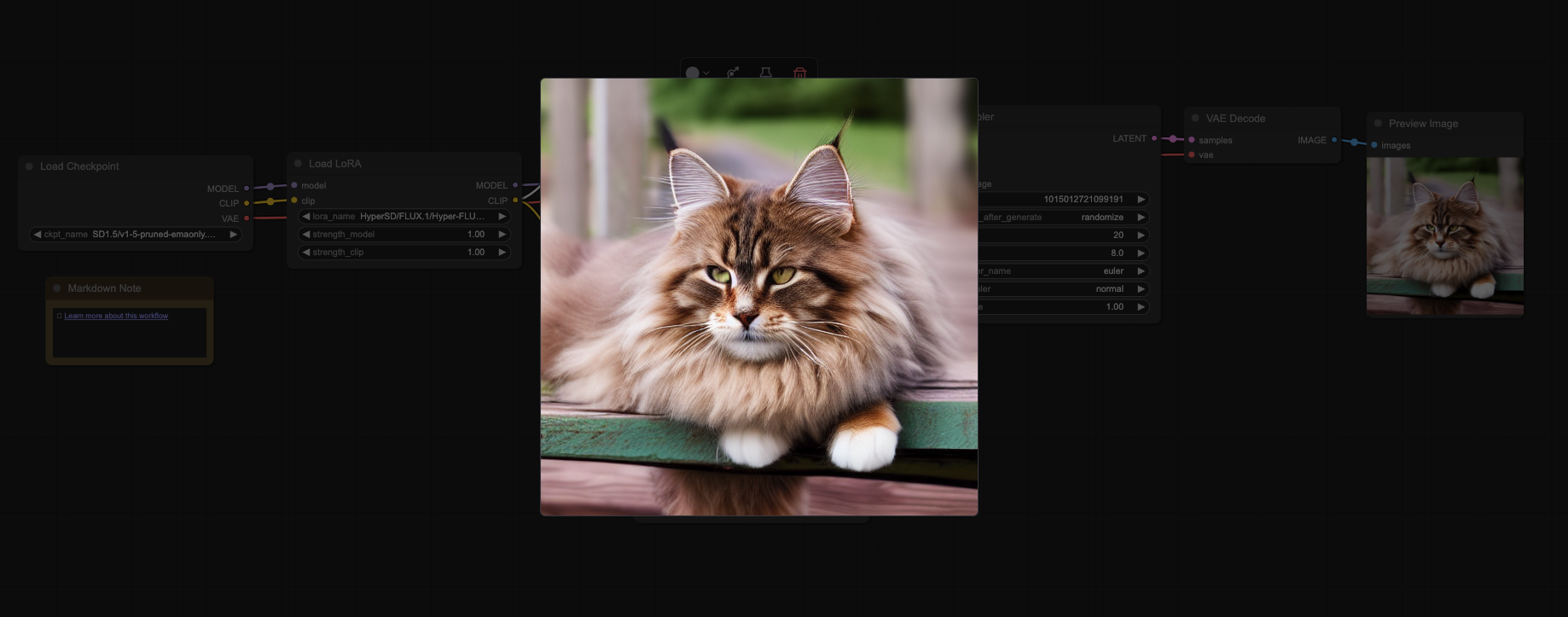
ComfyUI節點界面功能說明
1019
中文(繁體)
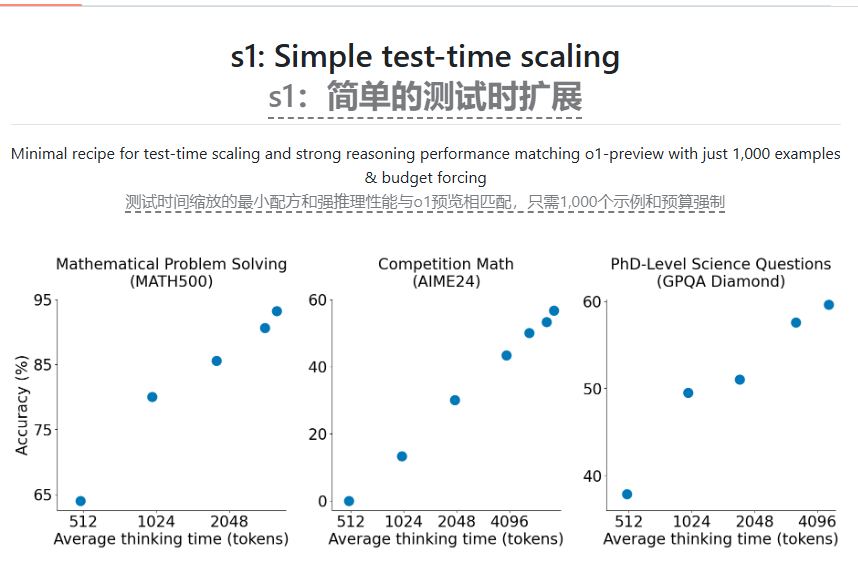
近期,斯坦福大學和華盛頓大學的AI 研究人員成功訓練出了一款名為s1的AI 推理模型,訓練成本不足50美元,所需的雲計算信用額度也非常低。這項研究成果於上週五發布,表明s1在數學和編程能力測試上表現不遜於OpenAI 的o1模型和DeepSeek 的R1模型。 s1的代碼和數據已在GitHub 上公開,供其他研究者使用。
研究團隊表示,他們從一個現成的基礎模型出發,通過蒸餾技術進行微調,以提取出所需的推理能力。 s1的蒸餾過程使用了谷歌的Gemini2.0Flash Thinking Experimental 模型,這種方法與加州大學伯克利分校的研究人員上個月訓練另一款AI 推理模型時採用的方式相似,後者的訓練成本約為450美元。
這一成果讓許多人感到振奮,尤其是在如今的AI 領域,研究者們能夠在沒有巨額資金支持的情況下仍能進行創新。然而,s1的出現也引發了對AI 模型商品化的深思。若任何人都可以以相對較低的成本複制出多百萬美元的模型,那麼這些大公司的護城河究竟在哪裡呢?
顯然,大型AI 實驗室對此並不滿意,OpenAI 曾指控DeepSeek 不當使用其API 數據進行模型蒸餾。 s1的研究團隊希望能找到一種簡單的方法來實現強大的推理性能,同時提升“測試時間擴展” 能力,即讓AI 模型在回答問題之前有更多思考時間。這些都是OpenAI 的o1模型所取得的突破,DeepSeek 及其他AI 實驗室也嘗試用不同的方法進行複制。
s1的研究表明,通過一個相對小的數據集,使用監督微調(SFT) 方法可以有效蒸餾推理模型,而這種方法通常比DeepSeek 採用的大規模強化學習方法更便宜。谷歌也提供了對Gemini2.0Flash Thinking Experimental 的免費訪問,但該平台有每日使用限制,並且其條款禁止逆向工程其模型以開發競爭服務。
為了訓練s1,研究人員構建了一個包含1000個經過精心挑選的問題及其對應答案的數據集,同時附上了問題背後的“思考” 過程。訓練過程使用了16個Nvidia H100GPU,耗時不足30分鐘。根據研究人員的介紹,他們如今只需約20美元就能租到所需的計算資源。此外,研究團隊還使用了一個巧妙的技巧,讓s1在推理時添加“等待” 一詞,從而提升答案的準確性。
在未來的2025年,Meta、谷歌和微軟計劃在AI 基礎設施上投資數千億美元,其中部分資金將用於訓練下一代AI 模型。儘管蒸餾技術在以較低成本再現AI 模型的能力上展現出良好效果,但它並沒有顯著提升新的AI 模型的表現。
論文:https://arxiv.org/pdf/2501.19393
代碼:https://github.com/simplescaling/s1