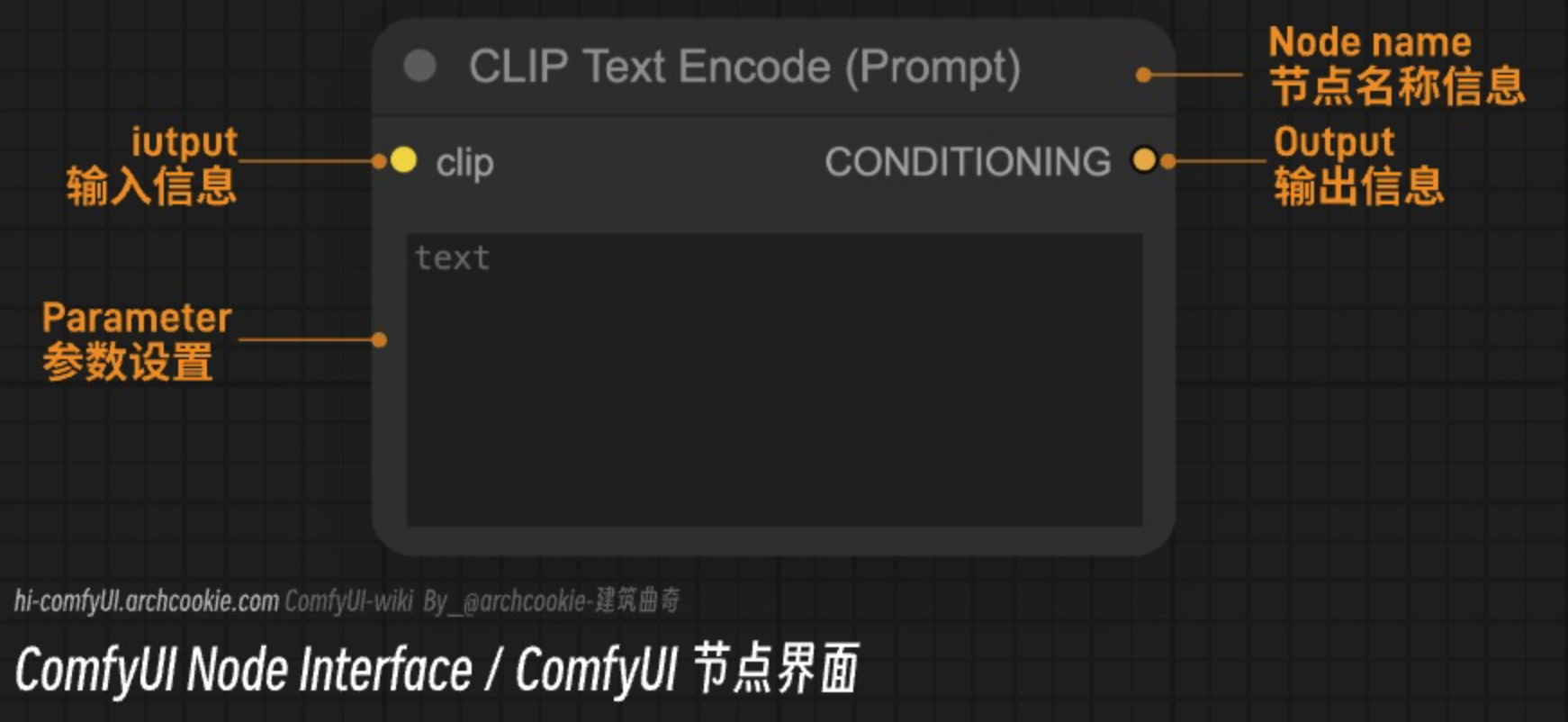
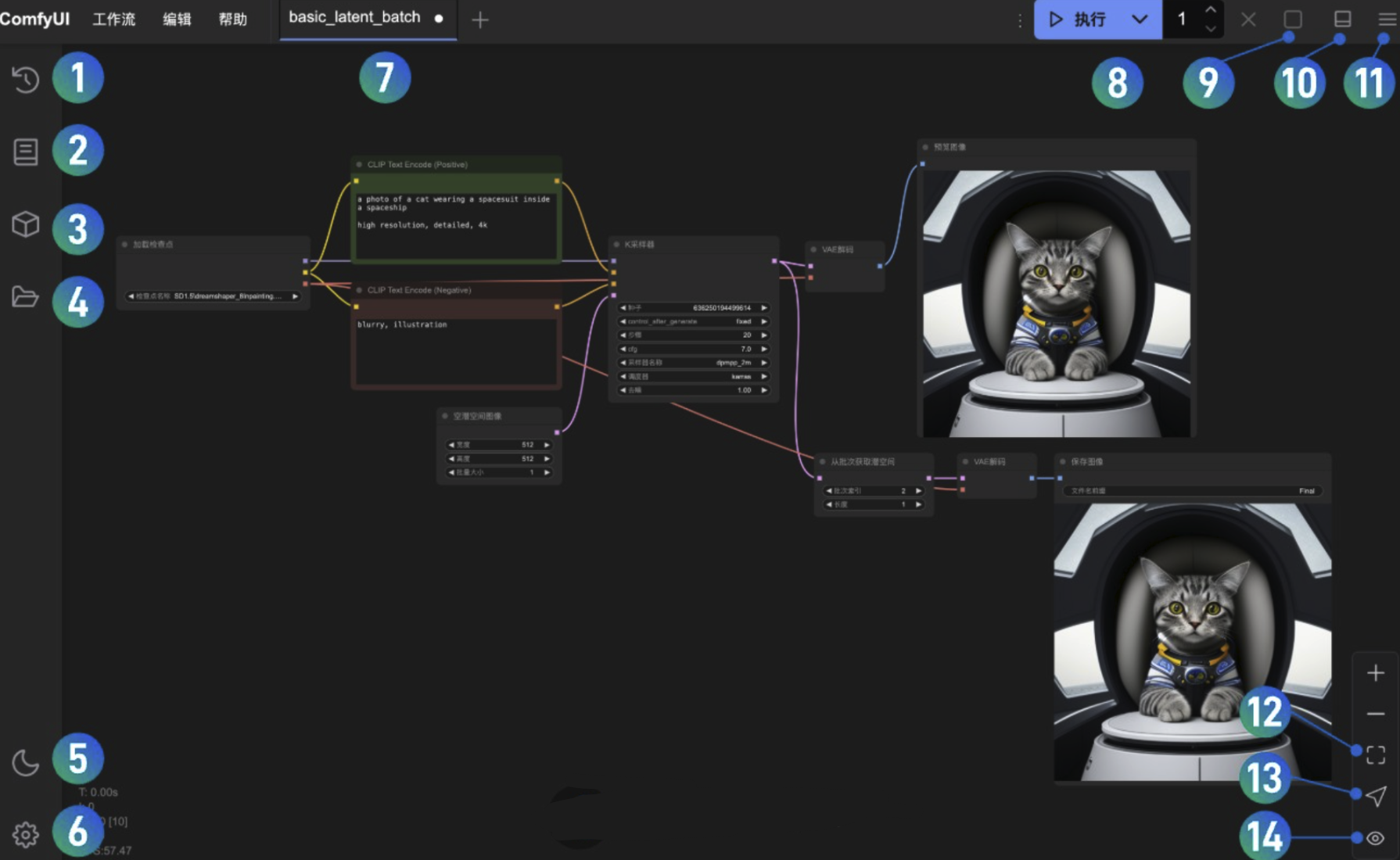
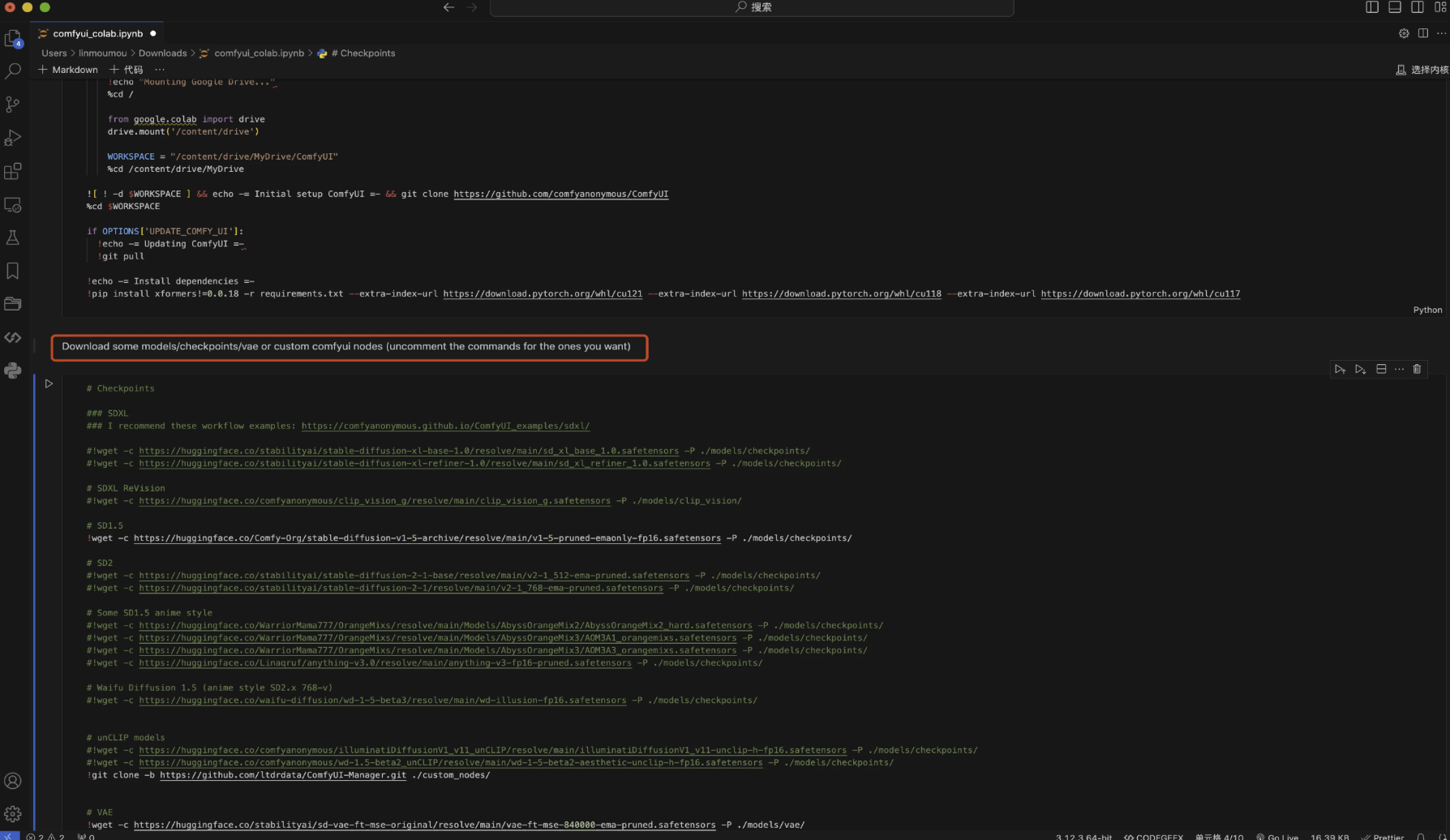
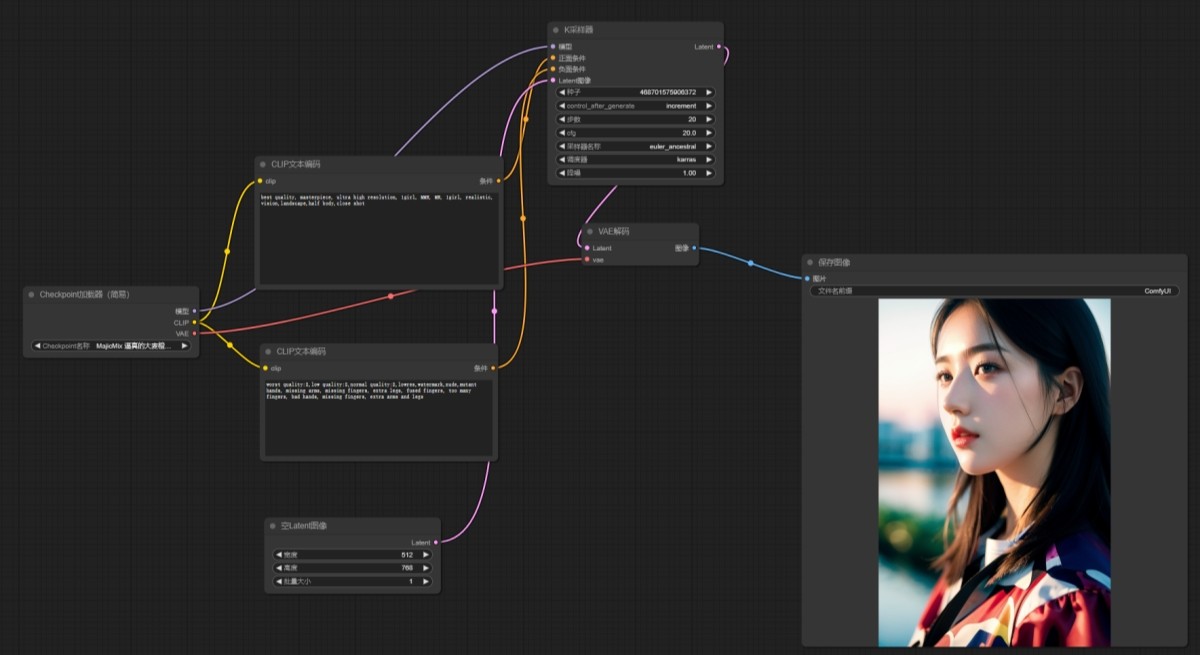
ComfyUI node interface function description
1019
English
Artificial Intelligence Company Anthropic recently announced a new security method called "physical classifier", which aims to protect the language model from malicious manipulation. This technology is specifically aimed at "general jailbreak" -the input method to systematically bypass all security measures to prevent the AI model from generating harmful content.
To verify the effectiveness of this technology, Anthropic conducted a large -scale test. The company recruited 183 participants and tried to break through its defense system within two months. Participants are required to input specific problems to try to make the artificial intelligence model CLAUDE3.5 answer ten prohibited questions. Although it provides a $ 15,000 bonus and a test time of about 3,000 hours, no participants can completely bypass Anthropic security measures.

Progress from challenges
The early version of Anthropic has two main problems: one is to misjudge too much harmless request as a dangerous request, and the other is that a large amount of computing resources are required. After improvement, the new version of the classifier has significantly reduced the misjudgment rate and optimized the calculation efficiency. However, automatic testing shows that although the improved system has successfully prevented more than 95% of jailbreak attempts, an additional 23.7% computing power is still needed to run. In contrast, an unprotected Claude model allows 86% of jailbreak attempts to pass.
Training based on synthetic data
The core of the "constitutional classifier" is to distinguish the predefined rules (called the "Constitution") to distinguish the allowable and prohibited content. Systems use a variety of synthetic training examples of languages and styles to identify suspicious inputs in the training classifier. This method not only improves the accuracy of the system, but also enhances its ability to deal with diversified attacks.
Despite significant progress, researchers of Anthropic admitted that the system was not perfect. It may not be able to deal with all types of general jailbreak attacks, and new attack methods may appear in the future. Therefore, Anthropic recommends combined with "physical classifiers" with other security measures to provide more comprehensive protection.
Public test and future outlook
In order to further test the strength of the system, Anthropic plans to release a public demonstration version from February 3rd to 10th, 2025, inviting security experts to try to crack. The test results will be announced in subsequent updates. This measure not only shows Anthropic's commitment to technical transparency, but also provides valuable data for the research in the field of AI security.
Anthropic's "constitutional classifier" marks the important progress of the security protection of AI models. With the rapid development of AI technology, how to effectively prevent models from being abused has become the focus of industry attention. Anthropic's innovation provides new solutions for this challenge, and also pointed out the direction for future AI security studies.