Manus Invitation Code Application Guide
1083
English
The nonprofit research lab of artificial intelligence startup Cohere released a multimodal “open” AI model, Aya Vision, this week. The lab claims that the model is leading the industry.
Aya Vision is capable of performing multiple tasks, including writing image descriptions, answering photos-related questions, translating text, and generating summary in 23 major languages. Cohere said they offer Aya Vision for free through WhatsApp, hoping to make it easier for researchers around the world to obtain technological breakthroughs.
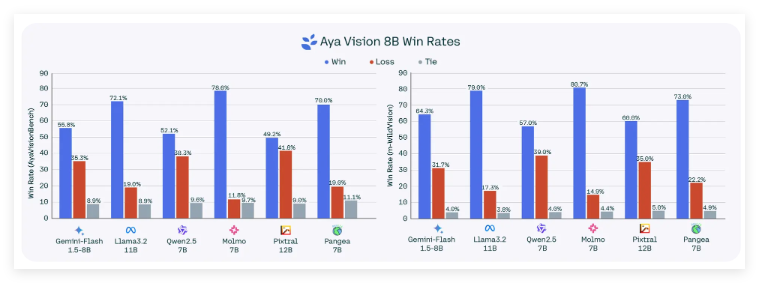
Cohere notes in his blog that despite significant progress in AI, there is still a large gap in model performance between different languages, especially in multimodal tasks involving text and images. “The goal of Aya Vision is to help close this gap.”
There are two versions of Aya Vision: Aya Vision32B and Aya Vision8B. The more advanced Aya Vision32B, known as the "new boundary", outperforms models twice its size in some visual understanding benchmarks, including Meta's Llama-3.290B Vision. At the same time, Aya Vision8B also outperforms some models with ten times its size in some evaluations.
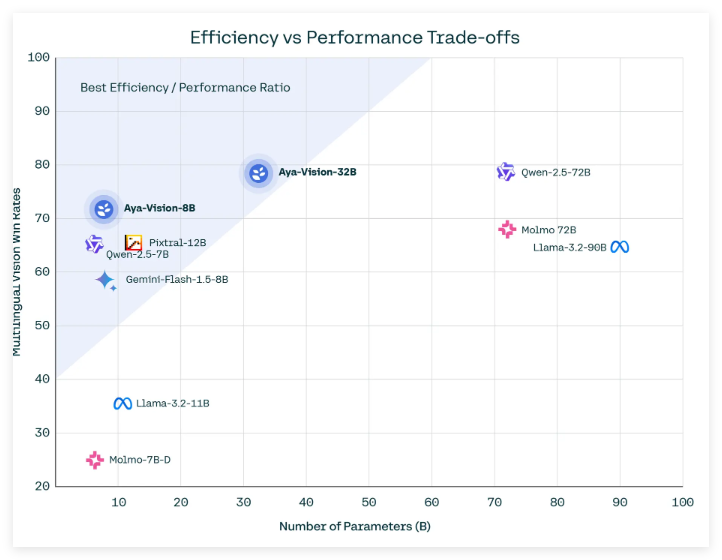
These two models are provided on the AI development platform Hugging Face under the Creative Commons4.0 license. Users are required to comply with Cohere's acceptable use appendix and are not available for commercial applications.
Cohere said Aya Vision's training uses a "diversified" English dataset that the lab translates and trains using synthetic annotations. Synthetic annotations refer to annotations generated by AI, which helps the model understand and interpret data during training. Despite potential drawbacks in synthetic data, competitors like OpenAI are increasingly using synthetic data to train models.
Cohere notes that training Aya Vision with synthetic annotations allows them to reduce resource usage while still achieving competitive performance. “This demonstrates our emphasis on efficiency and achieve more results with fewer computing resources.”
To further support the research community, Cohere has also released a new set of benchmark evaluation tools, AyaVisionBench, which aims to examine the capabilities of models in visual and language integration tasks such as identifying differences between two images and converting screenshots into code.
Currently, the AI industry is facing a so-called “assessment crisis”, which is mainly due to the widespread use of popular benchmarks whose overall scores are less relevant to the capabilities of tasks most AI users care about. Cohere claims that AyaVisionBench provides a "broad and challenging" framework for evaluating cross-lingual and multimodal understanding of models.
Official blog: https://cohere.com/blog/aya-vision








