Manus Invitation Code Application Guide
1078
English
Today, with the rapid development of artificial intelligence (AI) technology, the DeepSeek team has launched its new DeepSeek-V3/R1 inference system. This system aims to promote the efficient development of AGI (General Artificial Intelligence) through higher throughput and lower latency. To achieve this, DeepSeek adopts Expert Parallelism (EP) technology, significantly improving the computing efficiency of the GPU and expanding batch processing scale while reducing latency.
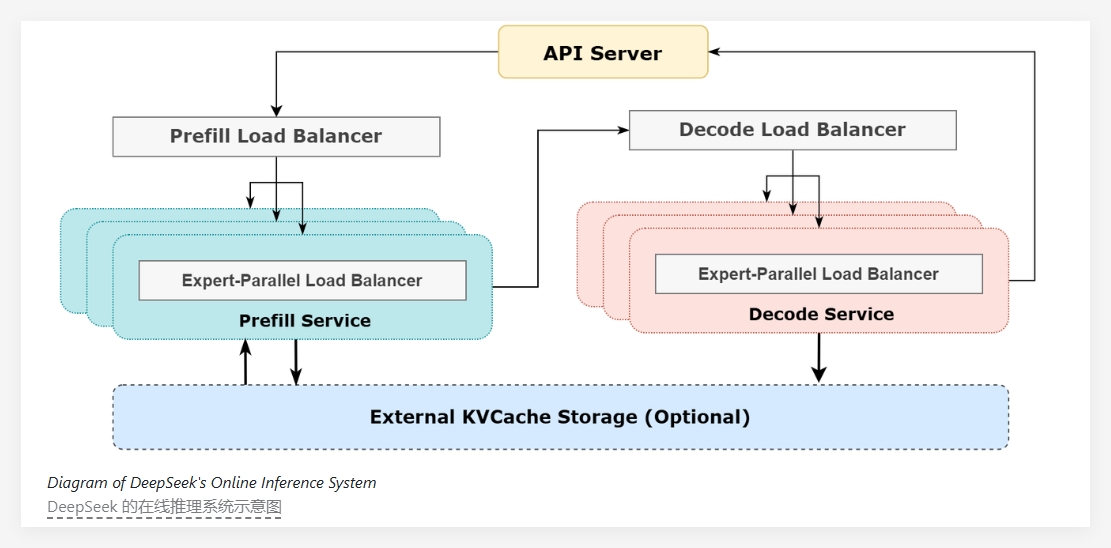
The core of DeepSeek-V3/R1 is its extremely high sparsity. Only 8 of 256 experts are activated per layer in the model, so a very large batch size is required to ensure that each expert has sufficient processing power. The architecture of this system adopts the prefill-decode disaggregation method, and adopts different degrees of parallelization strategies during the prefill and decoding stages.
During the pre-filling phase, the system hides the communication costs through a double batch overlap strategy, which means that when processing one batch of requests, the communication costs of another batch can be masked by the calculation process, thereby improving overall throughput. In the decoding stage, in response to the time imbalance in different execution stages, DeepSeek adopts a five-level pipeline method to achieve seamless communication and computing overlap.
To cope with the load inequality caused by large-scale parallelism, the DeepSeek team has set up multiple load balancers. These load balancers are committed to balancing computing and communication loads across all GPUs, avoiding a single GPU becoming a performance bottleneck due to overload operations, and ensuring efficient utilization of resources.
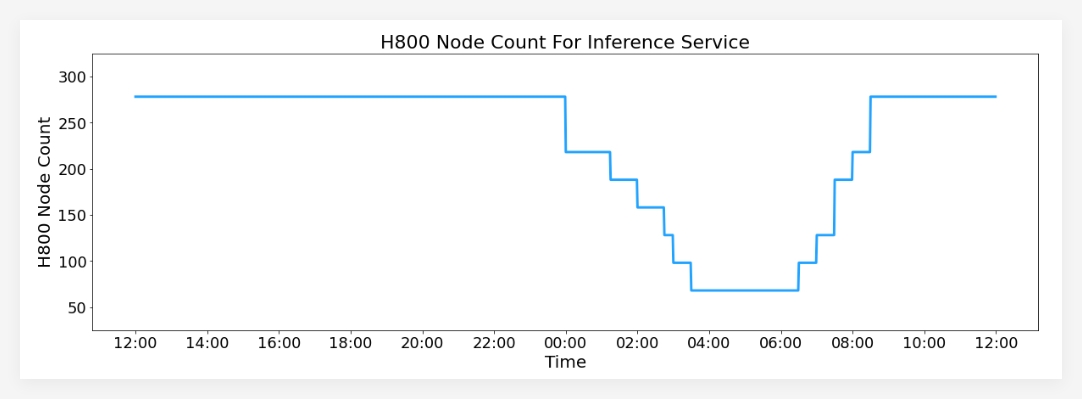
In terms of service performance, the DeepSeek-V3/R1 inference service runs on the H800GPU, using matrix multiplication and transmission formats consistent with the training process. According to the latest statistics, the system has processed 608 billion input tokens in the past 24 hours, with the highest node occupancy rate of 278, and the average daily occupancy rate of 226.75, and the overall service performance is good.
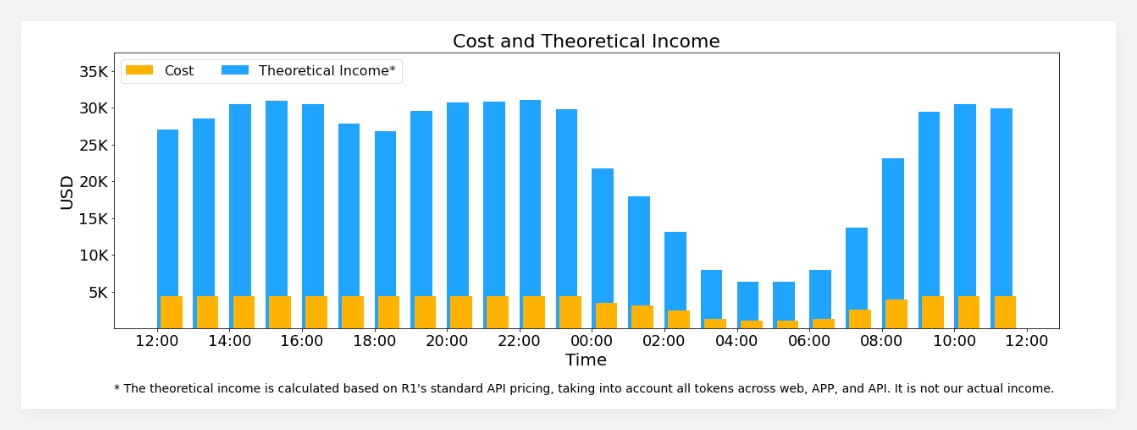
Through efficient architectural design and intelligent load management, the DeepSeek-V3/R1 inference system not only improves the inference performance of artificial intelligence models, but also provides strong infrastructure support for future AGI research and application.
Project: https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_inference_system_overview.md









