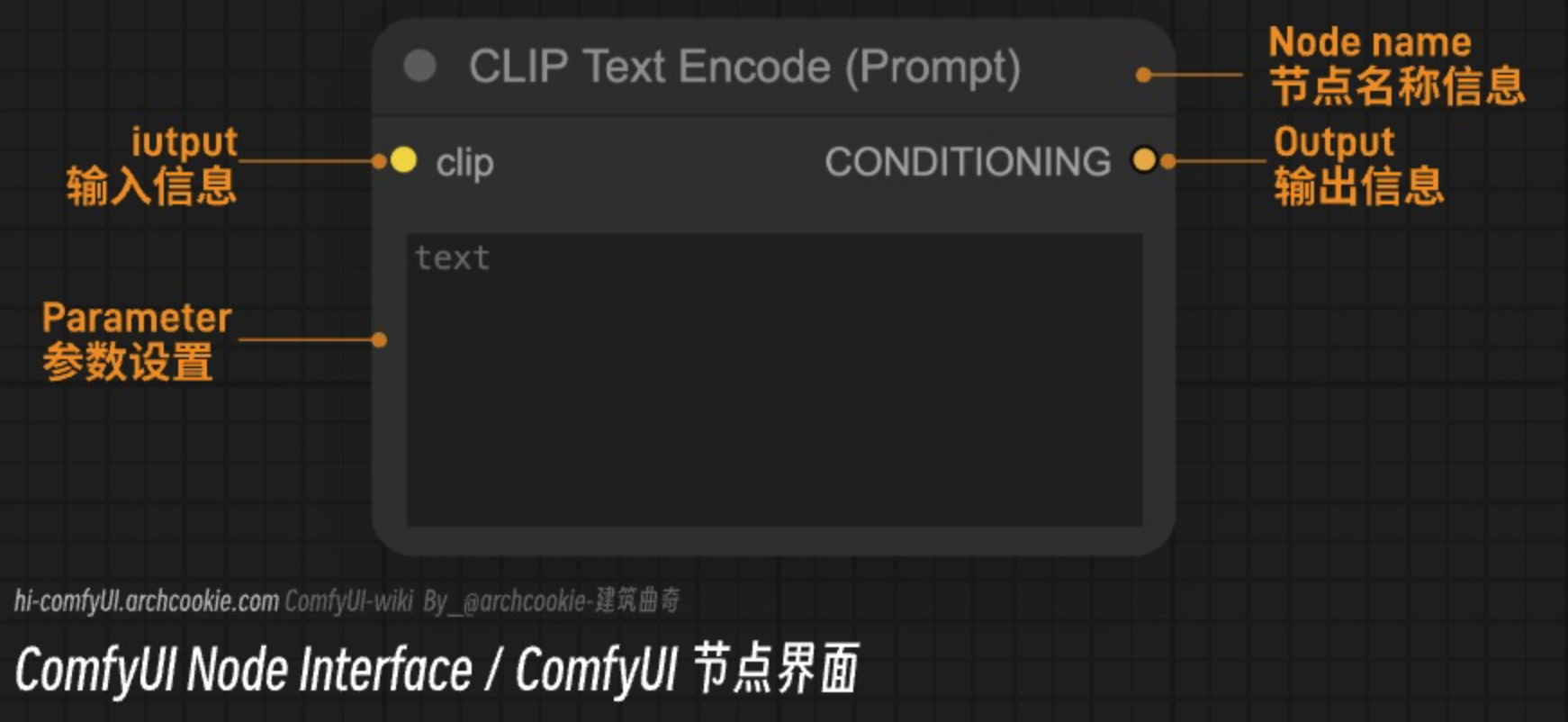
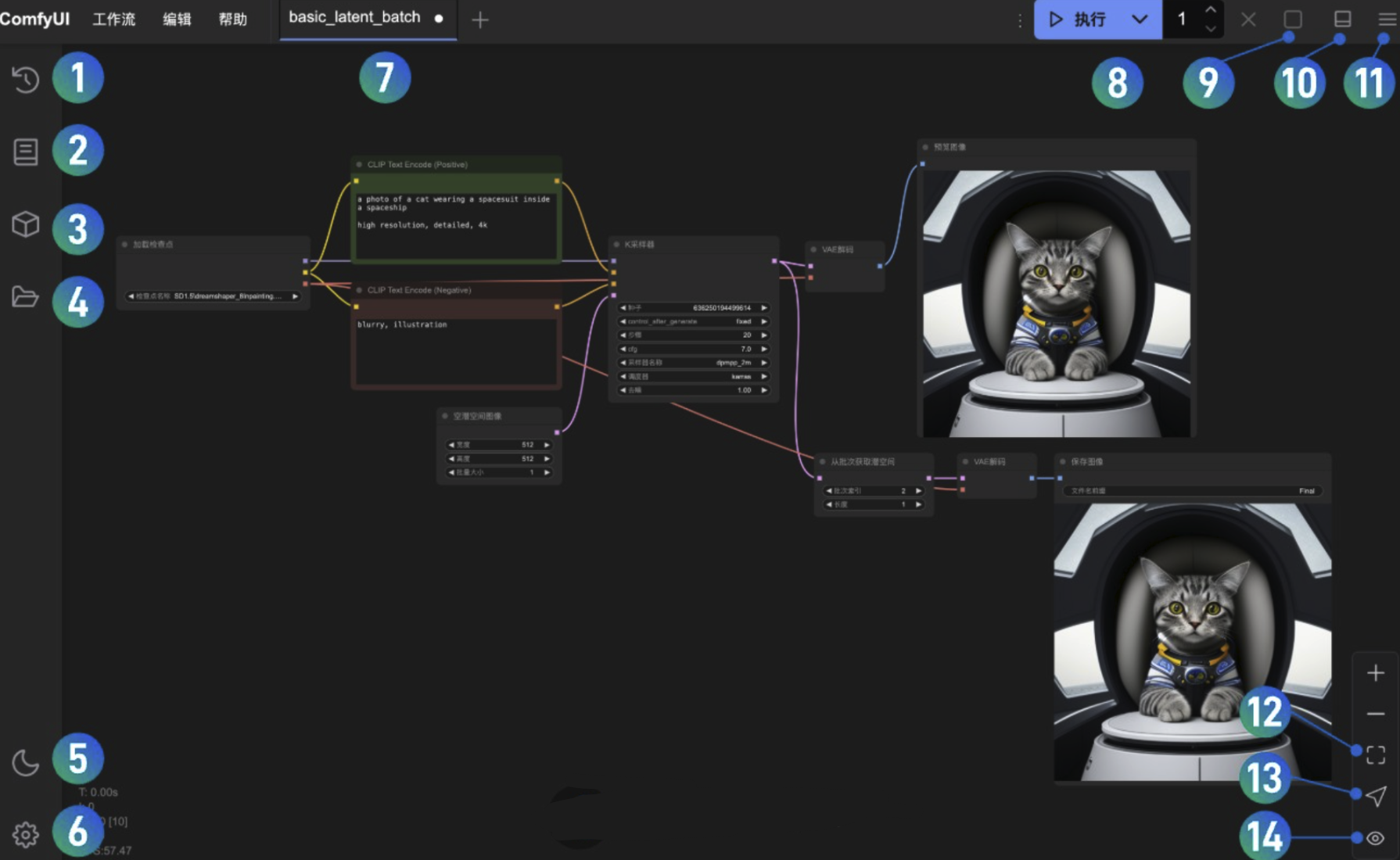
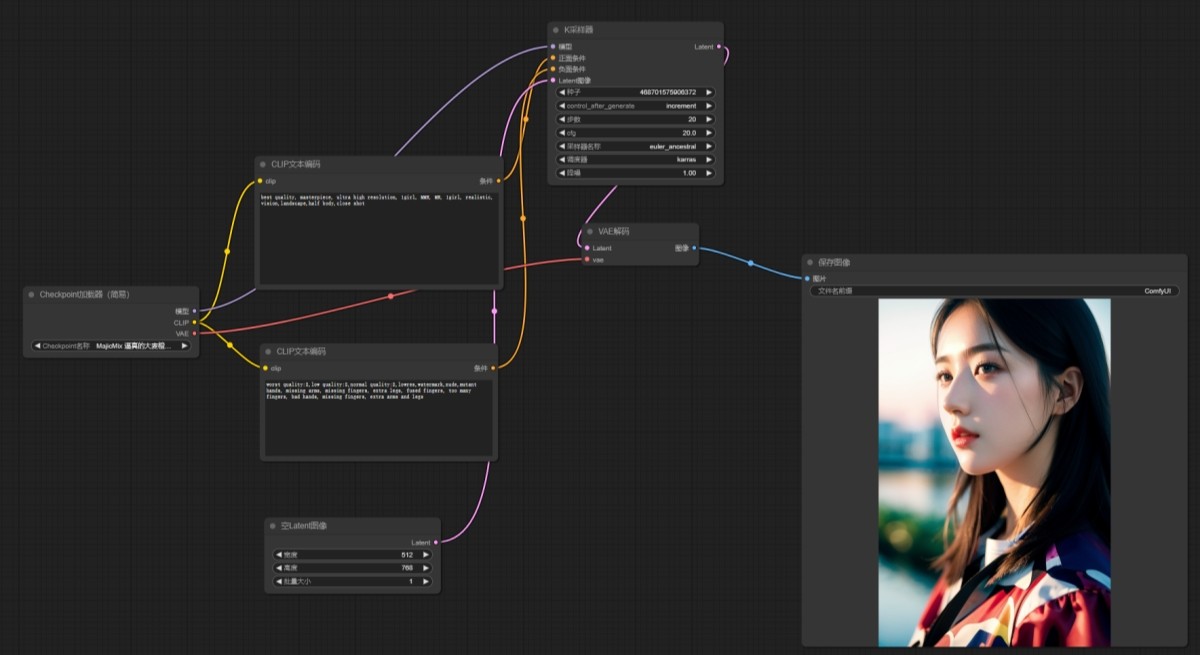
ComfyUI node interface function description
1013
English
With the continuous development of artificial intelligence technology, the integration of vision and text data has become a complex challenge. Traditional models often have difficulty accurately parsing structured visual documents such as tables, charts, infographics, and illustrations. This limitation affects automatic content extraction and understanding capabilities, and thus affects applications such as data analysis, information retrieval and decision-making. Faced with this demand, IBM recently released Granite-Vision-3.1-2B, a small visual language model designed for document understanding.
Granite-Vision-3.1-2B is capable of extracting content from a variety of visual formats, including tables, charts, and illustrations. The model is trained on a carefully selected data set, with data sources including public and synthetic sources, capable of handling a variety of document-related tasks. As an improved version of Granite's large language model, it integrates the two modalities of image and text, thereby improving the interpretation ability of the model and is suitable for a variety of practical application scenarios.
The model consists of three key components: first, the visual encoder, which efficiently processes and encodes visual data using SigLIP; second, the visual language connector, a double-layer multi-layer perceptron (MLP) with GELU activation function , aims to connect visual information with text information; finally, a large language model, based on Granite-3.1-2B-Instruct, has a context length of 128k, which can handle complex and huge inputs.
During training, Granite-Vision-3.1-2B draws on LlaVA and combines the characteristics of multilayer encoders, as well as denser grid resolution in AnyRes. These improvements enhance the model's ability to understand detailed visual content, allowing it to perform visual document tasks more accurately, such as analyzing tables and charts, performing optical character recognition (OCR), and answering document-based queries.
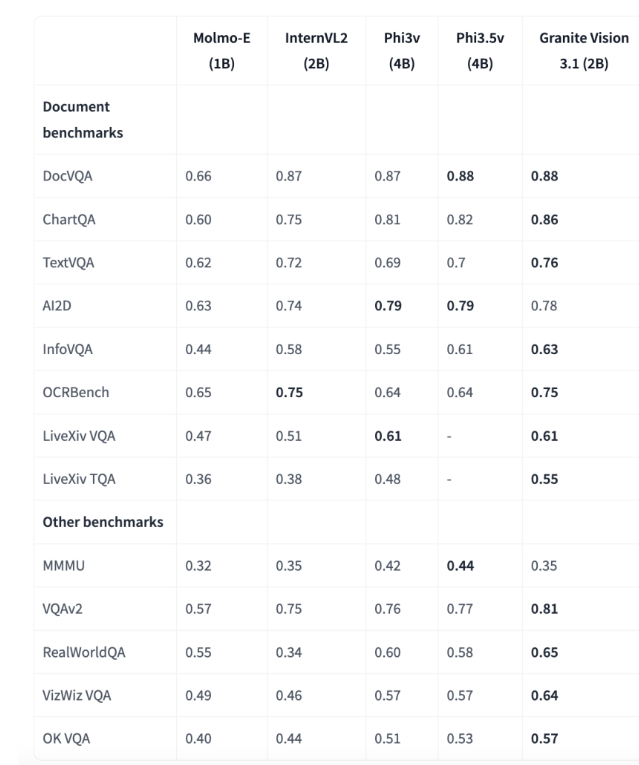
The evaluation results show that Granite-Vision-3.1-2B has performed well in multiple benchmarks, especially in document understanding. In the ChartQA benchmark, the model scored 0.86, surpassing other models with parameters in the 1B-4B range. In the TextVQA benchmark, the score is 0.76, showing strong ability to parse and answer text information embedded in images. These results highlight the model's potential for precise visual and text data processing in enterprise applications.
IBM's Granite-Vision-3.1-2B represents an important advance in the visual language model and provides a balanced visual document understanding solution. Its architecture and training methods enable it to parse and analyze complex visual and text data efficiently. Thanks to its native support for transformers and vLLM, the model can be adapted to a variety of use cases and can be deployed in cloud environments such as Colab T4, providing researchers and professionals with a practical tool to enhance AI-driven document processing capabilities .
Model: https://huggingface.co/ibm-granite/granite-vision-3.1-2b-preview