Manus Invitation Code Application Guide
1088
English
Sesame's latest voice synthesis model "Conversational Speech Model" (CSM) has recently sparked heated discussion on the X platform and is known as "a voice model that is like a real person speaking." With its amazing nature and emotional expression ability, this model not only makes users "can no longer distinguish" its differences from humans, but also claims to have successfully crossed the "uncanny valley effect" in the field of voice. With the spread of demonstration videos and user feedback, CSM is quickly becoming a new benchmark for AI voice technology.

Crossing the "Underworld Valley": CSM's technological breakthrough
The "Underworld Effect" refers to the inconvenience of human discomfort when artificially synthesized voice or image is close to real humans but there are still subtle differences. Sesame deals with this problem head-on through its CSM model. X user @imxiaohu posted on March 1: "Brothers, this brand new voice model is amazing and can no longer be distinguished!" He pointed out that CSM has excellent performance in personality, memory, expression ability and contextual appropriateness, almost eliminating the mechanical feeling of traditional voice assistants.
The Sesame team stated in an official research article that the goal of CSM is to achieve a "voice presence" - making voice interactions not only true and trustworthy, but also understand and valued. This breakthrough is due to its core components: emotional intelligence (interpretation and response to emotions), context memory (adjusting the output based on dialogue history), and high-fidelity voice generation technology. During the demonstration, CSM showed a natural tone and emotional side in the ultra-long conversation, and users could not even distinguish it as AI without knowing it.
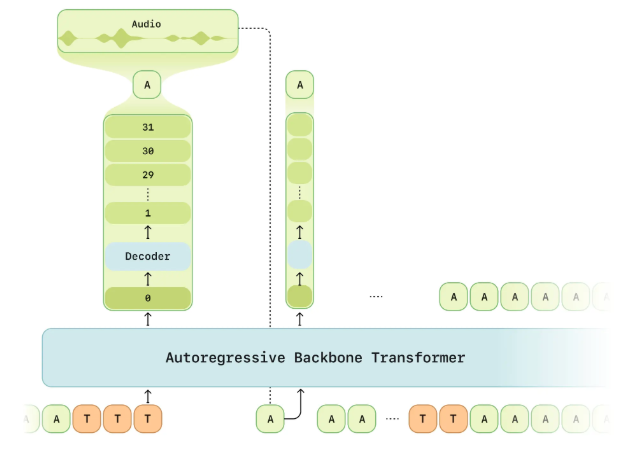
Realistic user experience
User feedback on the X platform further confirms CSM's amazing performance. @imxiaohu shared a super long dialogue demonstration in the post, covering a variety of scenes and scenarios, and lamented: "The tone and emotion are very, very close to humans in some expressions, hahahaha." He mentioned that in the absence of prompts, the output of this model has made it difficult to distinguish between true and false. Another user @leeoxiang said on March 1 that he practiced speaking English with CSM for half an hour, and almost no delay was felt. He said that his "costicism is done very well and there will be some tone in it", and his ability to actively talk is also impressive.
The enthusiasm of the community is not limited to praise. Many users point out that CSM's dialogue fluency and emotional expression have surpassed existing mainstream models such as OpenAI's ChatGPT voice mode. @op7418
On February 28, researchers were recommended to pay attention to Sesame's technical articles and emphasize its unique voice authenticity evaluation system, showing the technical rigor of the model.
Still room for improvement: Sesame's future plans
Despite the shocking performance of CSM, Sesame officially admitted that this is not the end. @imxiaohu quoted the official statement and said, "This is not the most perfect, there is still a lot of room for improvement!" At present, CSM supports multiple languages such as English, but as @leeoxiang pointed out, Chinese is not yet supported. In addition, some users found in the test that the model's performance in specific contexts (such as foreign language switching or music singing) still has room for improvement.
Sesame has promised to open source some of its research results, and its GitHub page (SesameAILabs/csm) shows that CSM will be licensed under the Apache2.0. This move has aroused the expectations of the developer community, and many people hope to further promote the development of voice AI through in-depth research on its architecture.
Industry impact and prospects
The debut of CSM is not only a technical response to the “Unortal Valley Effect”, but also sets a new standard for AI voice interaction. Compared with Grok, Claude and other models, CSM has particularly outstanding advantages in real-time, low latency and emotional expression. X User @AbleGPT
On March 2, he said: "If you are studying AI pronunciation, I highly recommend reading this article." This reflects the inspirational significance of CSM in the technology circle.
With Sesame planning to expand language support and optimize models, CSM is expected to shine in areas such as education, entertainment and virtual companions. Judging from the enthusiastic response on X, this "brothers think it's amazing" voice model is redefining the way people interact with AI with realistic dialogue. In the future, can it completely eliminate the "uncanny valley" and become a true "digital partner"? The answer may be in the next iteration of Sesame.
Trial address: https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo








