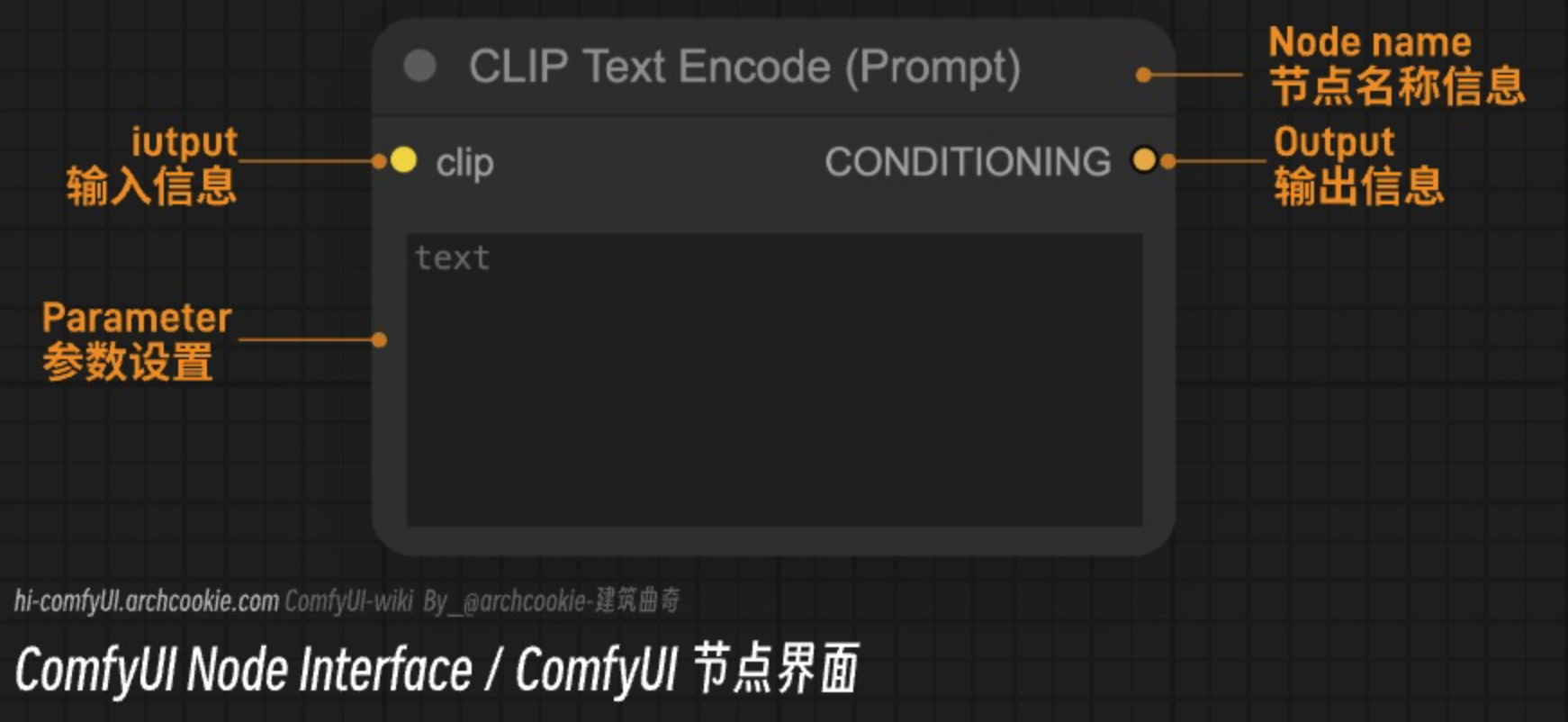
What should I do if the ComfyUI node reports an error? ComfyUI node error solution
1012
English
Recently, Beijing Dark Side of the Moon Technology Co., Ltd. announced that its smart assistant Kimi has received a major technological upgrade and launched a new k1.5 multi-modal thinking model. This model has reached industry-leading levels in multi-modal reasoning and general reasoning capabilities, marking another breakthrough for Kimi in the field of artificial intelligence.
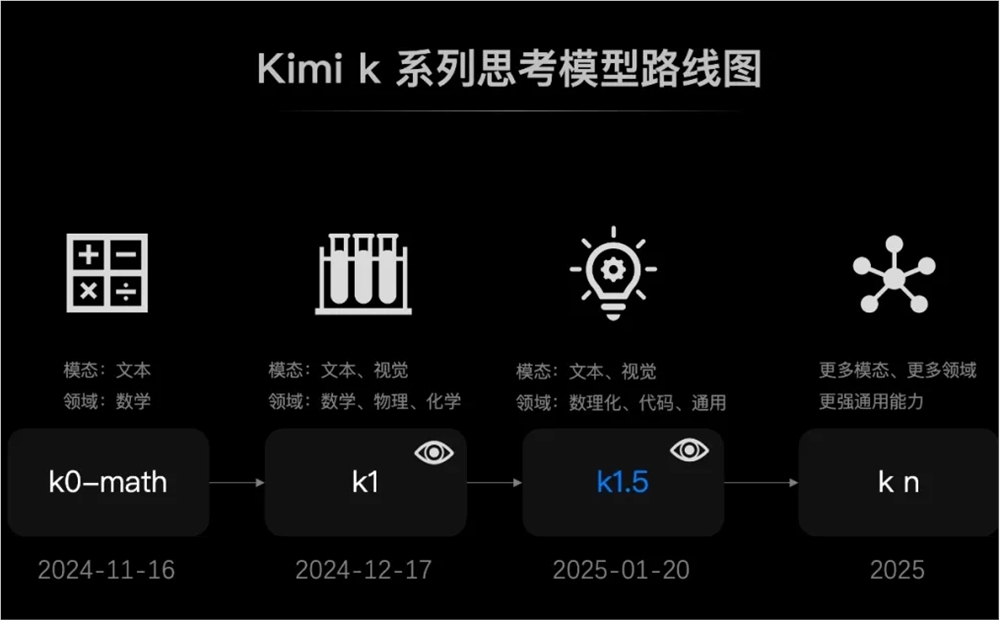
The k1.5 multimodal thinking model is Kimi’s third major upgrade to its k-series reinforcement learning model in just three months. Following the release of the k0-math mathematical model in November last year and the k1 visual thinking model released in December, the k1.5 model performed outstandingly in benchmark tests. In short-CoT mode, k1.5's mathematics, coding, visual multi-modal and general capabilities have greatly surpassed the levels of the global short-thinking SOTA models GPT-4o and Claude3.5Sonnet, with a lead of up to 550%. In long-CoT mode, k1.5's mathematics, code and multi-modal reasoning capabilities have also reached the level of the official version of OpenAI o1, a long-thinking SOTA model. This is the first time in the world that a company other than OpenAI has achieved the official version of o1. version of multi-modal reasoning performance.
Behind this upgrade is the unremitting efforts and innovation of Kimi's technical team. For the first time, the team published a detailed model training technology report "Kimi k1.5: Scaling to achieve reinforcement learning with the help of large language models", recording the exploration of model training under the new technology paradigm.
The report pointed out that the key innovations of the k1.5 model include long context expansion, which improves training efficiency through partial expansion technology. It is also observed that the increase in context length can continue to improve model performance. In addition, improved strategy optimization methods and concise framework design also provide support for the strong performance of the model. It is worth noting that the k1.5 model was jointly trained on text and visual data, and has the ability to jointly reason between the two modalities. It performs particularly well in mathematical abilities, although it is difficult to deal with geometric graphics problems that partially rely on graphic understanding. There are still challenges.
In order to further improve the short-chain thinking reasoning ability, the team also proposed an effective long2short method, using Long-CoT technology to improve the Short-CoT model, and achieved remarkable results in tests such as AIME, MATH500 and LiveCodeBench, significantly surpassing existing short-chain thinking methods. Chain thinking models, such as GPT-4 and Claude Sonnet3.5.
The preview version of the k1.5 multimodal thinking model will be launched in grayscale on the Kimi.com website and the latest version of the Kimi smart assistant app. If users find the model switching button during use, they can experience this newly upgraded model. The k1.5 model is good at deep reasoning and can help users solve complex code problems, mathematical problems and work problems.
Dark Side of the Moon Technology Co., Ltd. stated that it will continue to accelerate the upgrade of the k-series reinforcement learning models along the established roadmap in 2025, bringing more modalities, capabilities in more fields and stronger general capabilities, unlocking more for users possibility.
github report link: https://github.com/MoonshotAI/kimi-k1.5