Manus Invitation Code Application Guide
1080
English
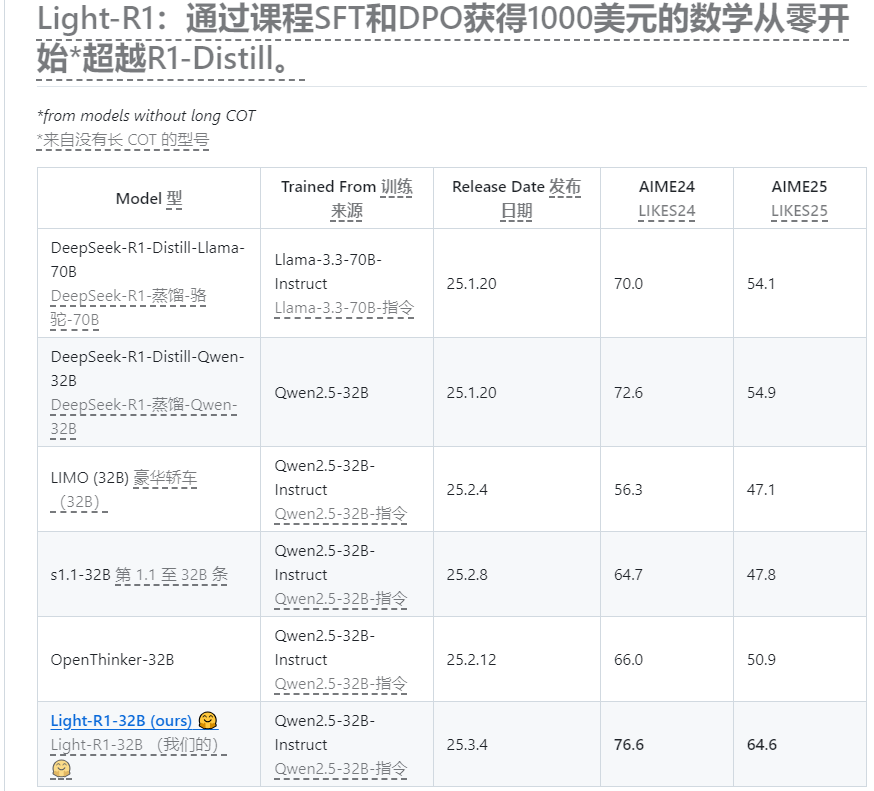
On March 6, 2025, a new language model called **Light-R1-32B** was officially unveiled. This mathematical problem-solving tool based on the **Qwen2.5-32B-Instruct** model has been specially trained and has become a highlight in the field of artificial intelligence with its excellent mathematical problem-solving ability, low training cost and reproducibility. Development team xAI said that Light-R1-32B not only surpasses similar models in performance, but also provides a valuable reference for academic research and practical applications.
Excellent mathematical problem-solving ability
The core advantage of Light-R1-32B lies in its excellent mathematical problem-solving performance. In authoritative math competition tests such as AIME24** and AIME25**, the model showed better results than the **DeepSeek-R1-Distill-Qwen-32B**. What is even more remarkable is that this achievement is achieved based on "start from scratch" training, that is, using initial models that do not have long-chain thinking ability, gradually upgrade to the current level through unique methods. This breakthrough proves the great potential of Light-R1-32B in complex inference tasks.
Coexistence of low cost and reproducibility
In the field of artificial intelligence, model training is often accompanied by high costs. However, Light-R1-32B breaks this convention, and its training costs are only about $1,000, which greatly lowers the development threshold. More importantly, the development team exposes all training data, code and training processes. This transparency not only facilitates other researchers to reproduce the model, but also provides a solid foundation for further optimization and expansion, and is a model of the open source spirit.
Innovative training methods: Course learning and thinking chain reinforcement
The success of Light-R1-32B is inseparable from its innovative training strategies. The development team adopted the ** course learning method to improve model performance step by step through **Supervised Fine Tuning (SFT)** and **Direct Preference Optimization (DPO). It is particularly worth mentioning that the model's Chain of Thought ability is particularly strengthened during the training process. By forcibly adding the **<think>** tag to the prompt word, the model is guided to generate a detailed reasoning process, thereby significantly improving the logic and accuracy of the problem-solving.
Data cleaning ensures fairness
To ensure the fairness of the evaluation results, Light-R1-32B conducted a thorough data cleaning during the data preparation phase. The development team eliminated samples that could cause data contamination, avoiding the cross-effect of training data and test data. This rigorous attitude further enhances the credibility of the model in practical applications.
Future Outlook
The release of Light-R1-32B not only injects a new trend into the field of solving mathematical problems, but also sets a benchmark for the low-cost development of artificial intelligence. Whether academic researchers or industry practitioners, they can explore more possibilities by reproducing and optimizing this model. xAI said that it will continue to improve Light-R1-32B in the future to promote its widespread application in the fields of education, scientific research and engineering.
Light-R1-32B redefines the value of mathematical problem-solving models with its low cost, high performance and strong thinking chain. As its name suggests, it is like a beam of light that illuminates a new path to the combination of artificial intelligence and mathematics.
Address: https://github.com/Qihoo360/Light-R1








