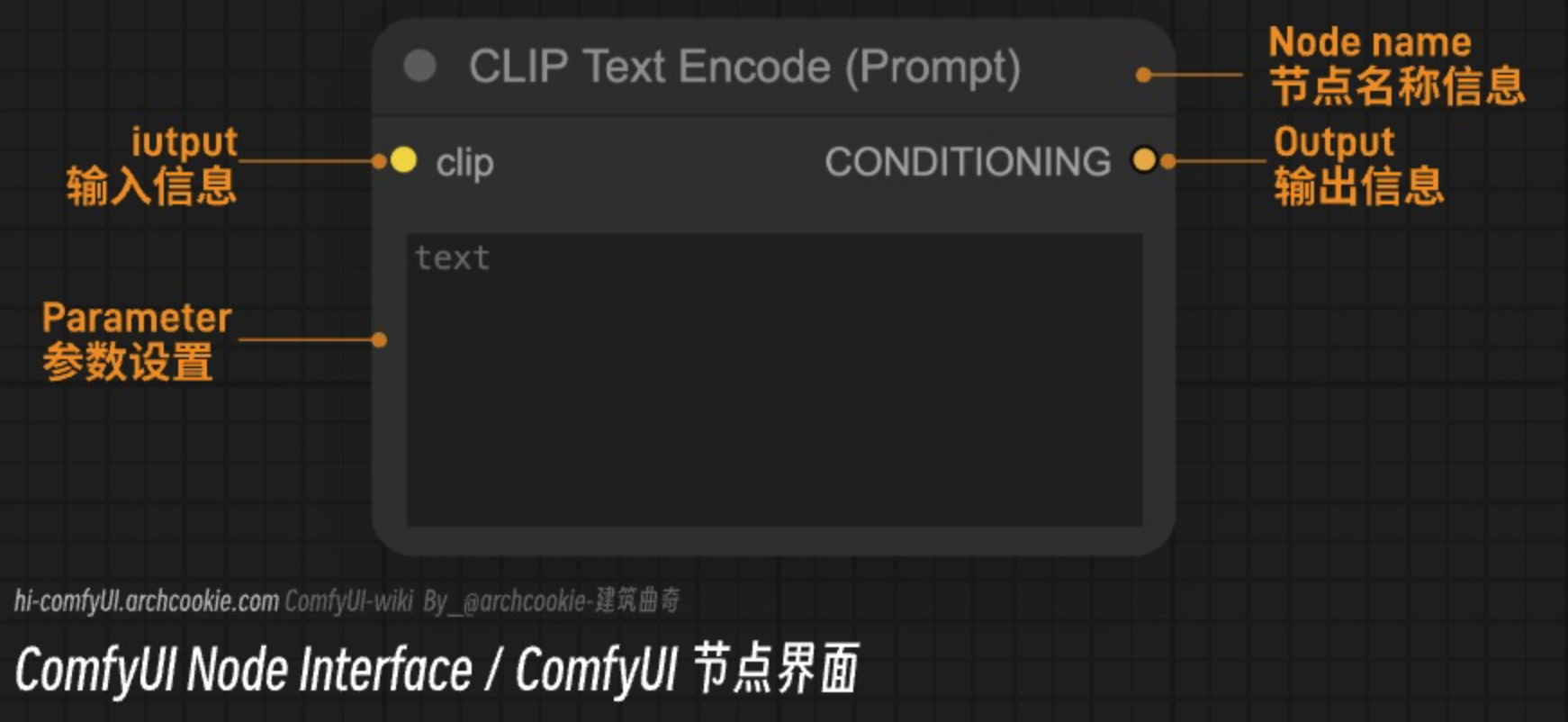
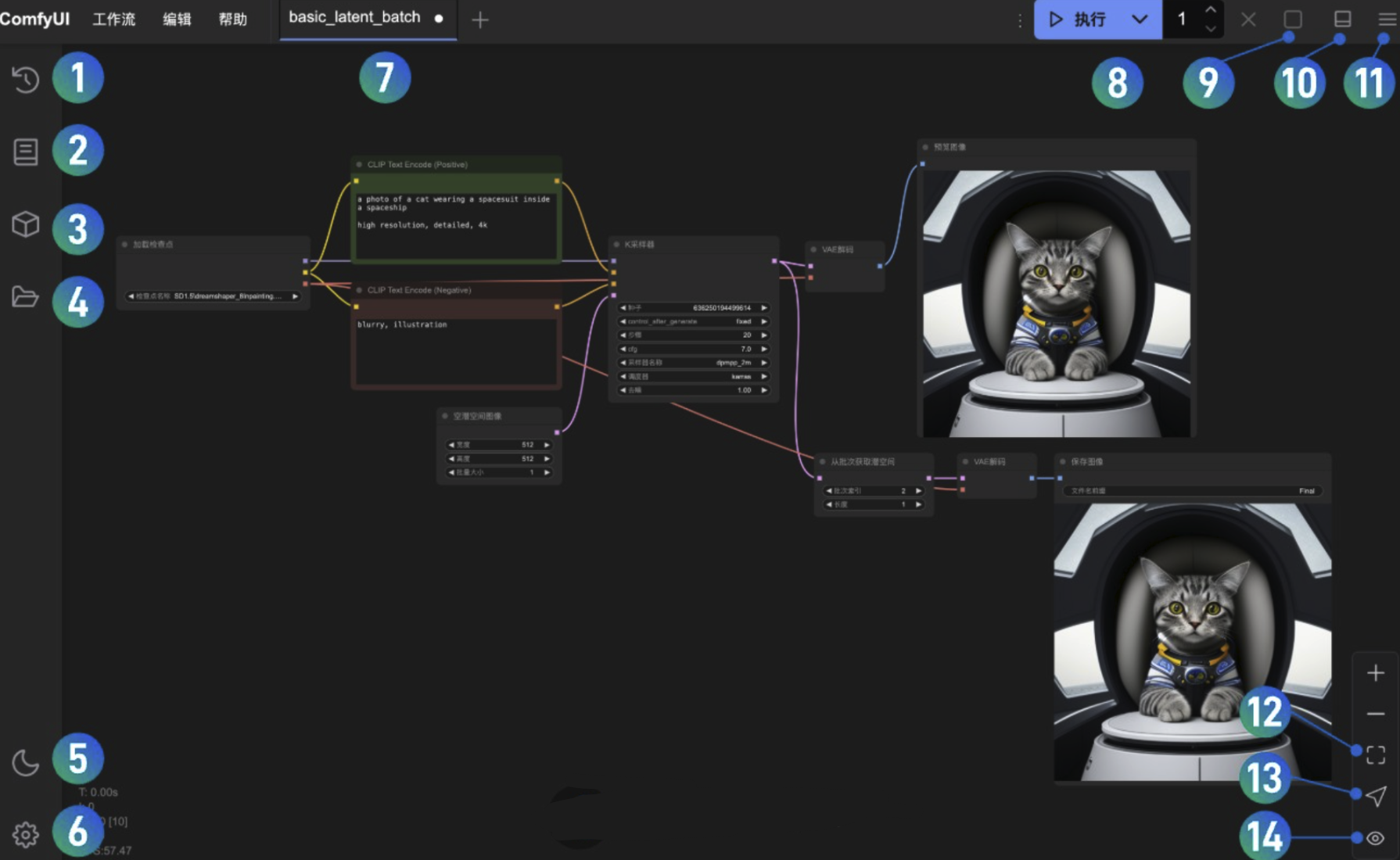
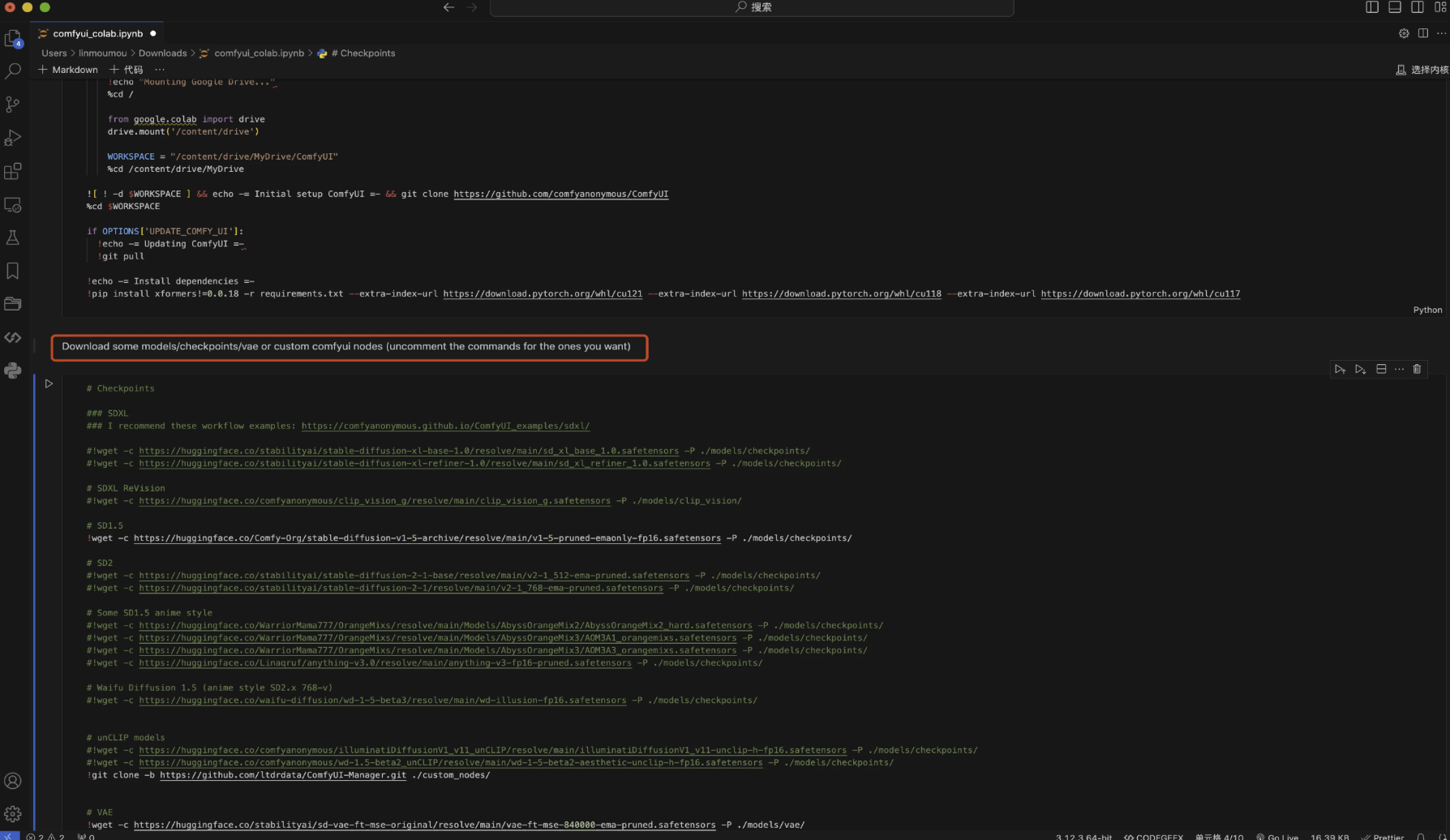
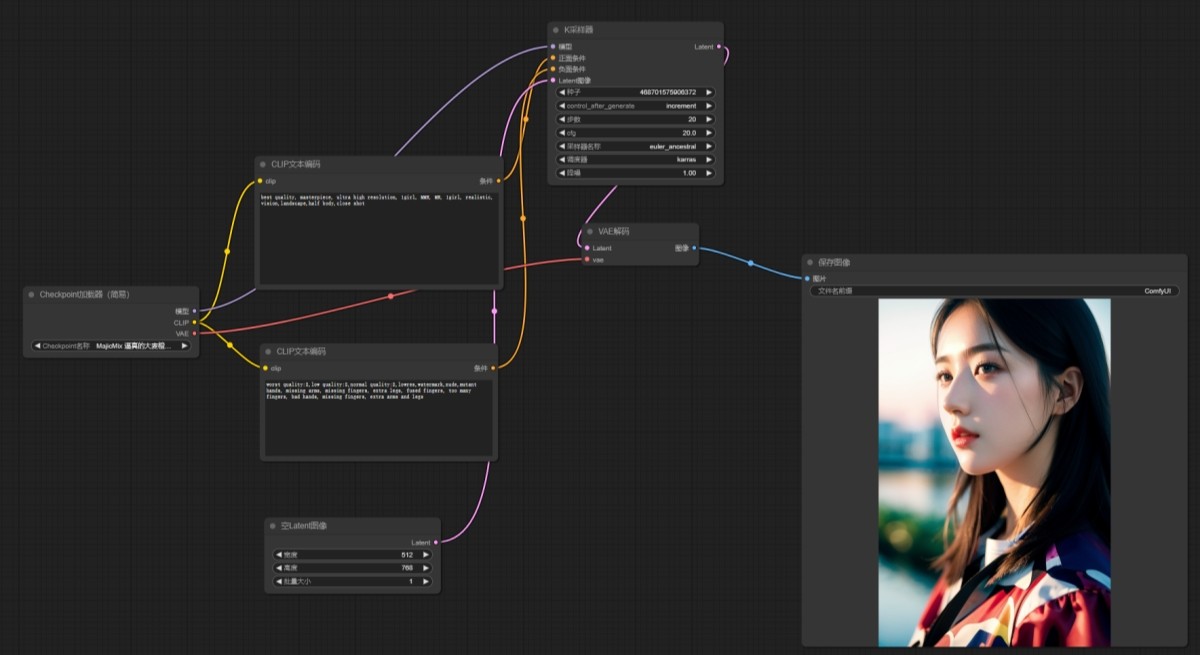
ComfyUI node interface function description
1014
English
Recently, Meta's approach to artificial intelligence training has attracted widespread attention. According to a lawsuit, the company is accused of downloading a large number of pirated e-books and articles without authorization to train its artificial intelligence models. At the heart of the incident were several leaked emails that provided further evidence for Meta's actions.

Meta admitted downloading a controversial large dataset called LibGen that contains tens of millions of pirated books, the email showed. According to court documents filed by the plaintiff, Meta downloaded at least 81.7TB of data from multiple shadow libraries, including at least 35.7TB of data from Z-Library and LibGen through a website called Anna's Archive. In addition, Meta previously downloaded 80.6TB of data from LibGen. These figures show that Meta's scale in this illegal act is amazing. The plaintiff pointed out that while other small-scale piracy has led to legal prosecution, Meta's behavior has become more serious.
In the content of the email, Meta employees also expressed concerns about the legal risks of their actions. In April 2023, Nikolai Bashlikov, a research engineer at the company, said: "It feels inappropriate to use the company's laptop to get BT." By September 2023, Bashlikov's opposition to this More obvious and consulted the legal team. He noted that "using Torrents means 'seed' the file, i.e. sharing content externally. This is legally not allowed." However, despite such warnings, Meta seems to have decided to conceal its download and sharing activities, and Minimize traceability of "seed" behavior by editing settings.
Meta is also said to have tried to reduce the risk of being traced to its servers by downloading datasets to non-Meta servers. This series of behaviors has triggered deep reflections on Meta's data use and copyright.