Google holds 14% of Anthropic equity, with a total investment of over US$3 billion
640
English
Visual language models (VLMs) play a crucial role in multi-modal tasks, such as image retrieval, image description, and medical diagnosis. The goal of these models is to align visual data with linguistic data to enable more efficient information processing. However, current VLMs still face significant challenges in understanding negation.
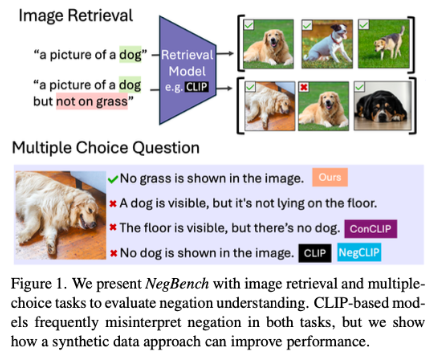
Negation is crucial in many applications, such as distinguishing between a "room without windows" and a "room with windows". Despite significant progress in VLMs, the performance of existing models drops significantly when dealing with negative statements. This limitation is particularly important in high-risk areas such as security surveillance and healthcare.
Existing VLMs, such as CLIP, employ a shared embedding space to align visual and textual representations. While these models perform well on tasks such as cross-modal retrieval and image captioning, they fail when dealing with negative sentences. The root of this problem is a bias in the pre-training data, which consists primarily of positive examples, causing the model to treat negative and positive statements as synonymous. Therefore, existing benchmarks, such as CREPE and CC-Neg, employ simple template examples that cannot truly reflect the richness and depth of negation in natural language. This makes VLMs face huge challenges when performing precise language understanding applications, such as querying complex conditions in medical imaging databases.
To address these issues, researchers from MIT, Google DeepMind, and the University of Oxford proposed the NegBench framework to evaluate and improve VLMs' ability to understand negation. The framework evaluates two basic tasks: Retrieval and Negation (Retrieval-Neg), which tests the model's ability to retrieve images based on positive and negative descriptions; and Multiple Choice Questions and Negation (MCQ-Neg), which evaluates the model's performance on subtle understanding. NegBench uses large synthetic datasets, such as CC12M-NegCap and CC12M-NegMCQ, containing millions of titles covering rich negative scenarios to improve model training and evaluation.
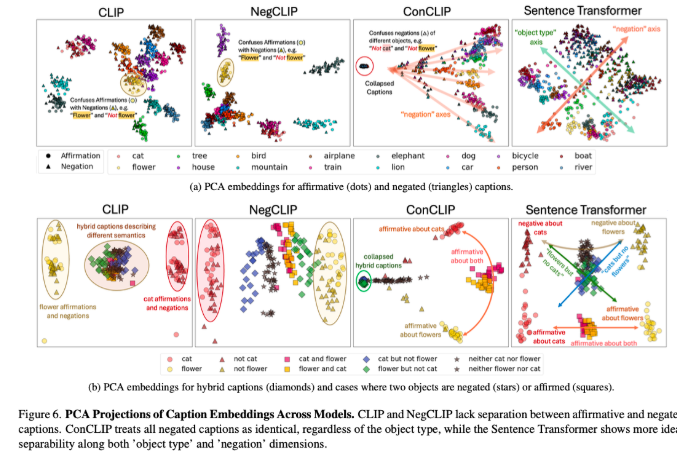
By combining real and synthetic datasets, NegBench effectively overcomes the limitations of existing models and significantly improves the model's performance and generalization capabilities. The fine-tuned model showed significant improvements in both retrieval and comprehension tasks, especially when dealing with negative queries, where the model's recall increased by 10%. In multiple-choice tasks, accuracy improved by as much as 40%, showing a greatly enhanced ability to distinguish between subtle positive and negative headlines.
The proposal of NegBench fills the key gap of VLMs in understanding negation and paves the way for building more powerful artificial intelligence systems, which is especially important in key fields such as medical diagnosis and semantic content retrieval.
Paper: https://arxiv.org/abs/2501.09425
Code: https://github.com/m1k2zoo/negbench