UBLIC Tiangongxing: The first full-size research-level humanoid robot below 300,000 yuan was released
657
English
Still being discouraged for video generation models that cost millions of dollars? Still lamenting that AI video creation is just a game for giants? Today, the open source community uses its strength to tell you: "No!" A new open source model called Open-Sora2.0 was born, completely subverting the "krypton gold" rules of video generation. It is unbelievable that this 11 billion parameter model with a performance of nearly commercial level actually cost only $200,000 (224 GPUs) to train successfully! You should know that those closed-source models that cost millions of dollars are simply ineffective in front of Open-Sora 2.0!
The release of Open-Sora2.0 is undoubtedly a "civilian revolution" in the field of video generation. It not only has strong strength comparable to or even surpasses the million-dollar model, but also reveals the model weight, reasoning code, and training process in an unprecedented open manner, completely opening up the "Pandora's Box" of high-quality video creation. This means that the once unattainable AI video generation technology is now within reach, and everyone has the opportunity to participate in this exciting creative wave!
GitHub open source repository: https://github.com/hpcaitech/Open-Sora
1. Hard-core strength: seeing is true, data speaks
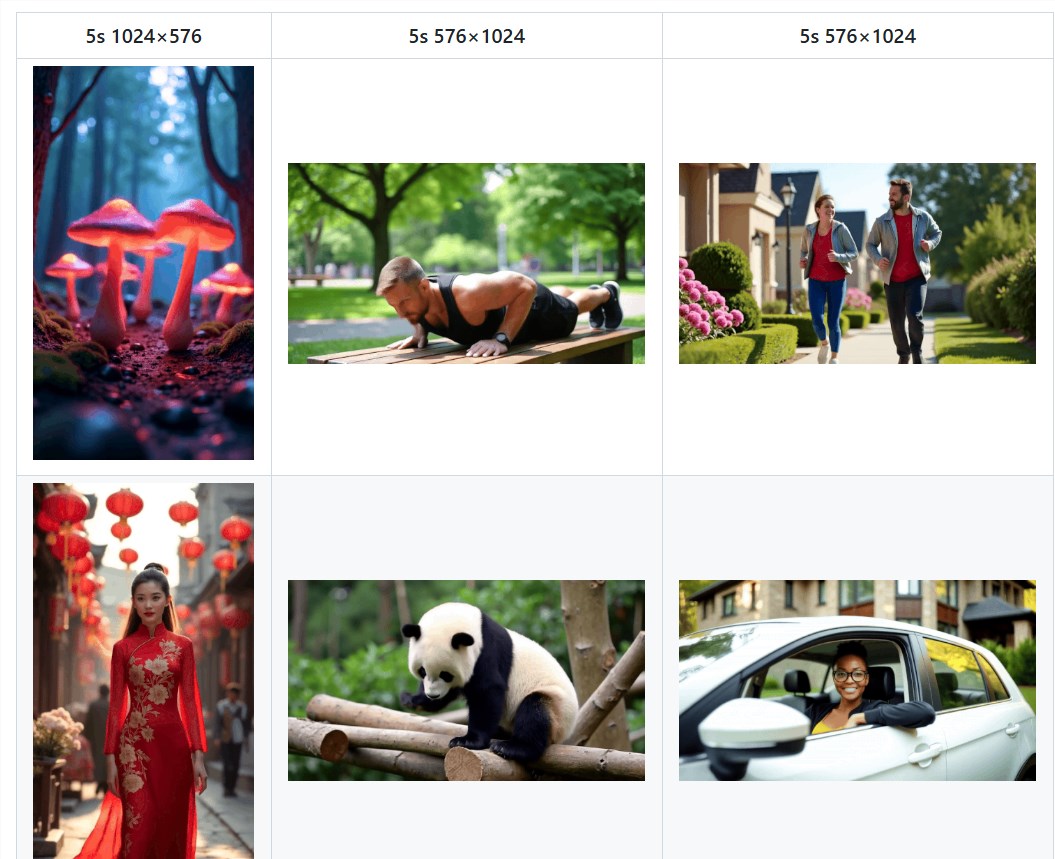
1.1 The effect explodes! Open-Sora2.0 video demo is a sneak peek
It’s nonsense to say it, but seeing it is true! How amazing is the generation effect of Open-Sora2.0? Just go to the demo video to let you “inspecify the goods”:
Move the mirror like a god! Accurately grasp the amplitude of movement: Whether it is the delicate movements of the characters or the grand scheduling of the scene, Open-Sora2.0 can accurately control the amplitude of movement like a professional director, and the picture expressiveness will be directly full!
The picture quality is superb! The smoothness is comparable to silky: 720p high-definition resolution, 24FPS stable frame rate, and the video generated by Open-Sora2.0 are impeccable in clarity and fluency, completely surpassing similar products on the market, and the visual experience "takes off" directly!
The scenes are ever-changing! The ability to control is full of flowers: pastoral scenery, urban night scenes, science fiction universe... Open-Sora 2.0 can easily pick up all kinds of complex scenes. The picture details are so rich that it is outrageous, and the camera is smooth and natural in use. It is simply "Leonardo da Vinci in the AI world"!
1.2 The parameter scale "makes big with small", and its performance is close to that of closed-source giants
Open-Sora2.0 is not a "flower" but a "technical hardcore" with real materials. With a parameter scale of only 11 billion, it bursts out with amazing energy. In the authoritative evaluation platform VBench and the subjective user review, it has achieved outstanding results that are enough to challenge closed-source giants such as HunyuanVideo and 30B Step-Video, which is a model of "making big with small profits"!
Users have the final say! Preference evaluation surpasses the heroes: In the three dimensions of visual effect, text consistency, and action performance, Open-Sora2.0 has at least two indicators that surpass the open source SOTA model HunyuanVideo, and even knocked down business models such as Runway Gen-3Alpha, proving with its strength that "there is good goods at low cost"!
VBench list "Strength Certification", performance approaches the ceiling: On the VBench list, the most authoritative VBench list in the field of video generation, the progress of Open-Sora2.0 can be called "Rockets' surge." From version 1.2 to version 2.0, the performance gap between it and the OpenAI Sora closed-source model has been reduced directly from 4.52% to 0.69%, which is almost negligible! What is even more exciting is that Open-Sora2.0 scores in VBench evaluation have surpassed Tencent HunyuanVideo, once again proving its huge advantage of "low input and high output", setting a new milestone for open source video generation technology!
2. Low-cost refining record: The technical password behind open source
Since its open source, Open-Sora has quickly become a "popular chicken" in the open source community with its efficient and high-quality video generation capabilities. But the challenge that follows is: how to break the curse of "high cost" for high-quality video generation so that more people can participate? The Open-Sora team faced the challenge and cut the model training cost by 5-10 times through a series of technological innovations! You should know that the training cost of one million US dollars on the market can be handled with just 200,000 US dollars, which is simply the "king of cost-effectiveness in the open source industry"!
Open-Sora not only open source model code and weight, but also generously subdue the full-process training code to build a vibrant open source ecosystem. In just half a year, Open-Sora's academic paper citations have approached 100 times, ranking among the top in the global open source influence list, surpassing all open source I2V/T2V video generation projects, and becoming the well-deserved "leader of open source video generation."
2.1 Model architecture: Inheritance and innovation at the same time
In terms of model architecture, Open-Sora2.0 not only inherits the essence of version 1.2, but also makes bold innovations: it continues the 3D autoencoder and Flow Matching training framework, and retains a multi-bucket training mechanism to ensure that the model can be "compatible" and handles videos of various lengths and resolutions. At the same time, a number of "black technologies" have been introduced to further improve the video generation capabilities:
3D full attention mechanism support: Capture time and space information in the video more accurately, making the generated video images more coherent and richer.
MMDiT architecture "God Assistance": More accurately understand the relationship between text instructions and video content, so that the semantic expression of Wensheng video is more accurate and in place.
The scale of the model has been expanded to 11B: Larger model capacity means stronger learning ability and generation potential, and video quality will naturally rise.
The FLUX model "bottomed", and the training efficiency "takes off": Drawing on the successful experience of the open source map-generated video model FLUX, model initialization is carried out, which greatly reduces the training time and cost, and allows the model training efficiency to "take the rocket".
2.2 Efficient training tips: Open source full process to help cost "successfully"
In order to push the training cost to the "floor price", Open-Sora2.0 has done a lot of homework in data, computing power, strategy, etc., and can be called "the money-saving expert in the open source industry":
Data is carefully selected and quality is selected: The Open-Sora team is well aware of the principle of "garbage in, garbage out", and conducts "carpet-style" screening of training data to ensure that every data is "high-quality" and improves model training efficiency from the source. The multi-stage and multi-level data screening mechanism, combined with various "black technology" filters, brings the quality of video data to a higher level and provides the best "fuel" for model training.
Computing power is "calculated carefully" and low-resolution training "takes the lead": The cost of high-resolution video training is much higher than that of low-resolution videos. The computing power gap between the two can reach up to 40 times! Open-Sora2.0 cleverly avoids "head-on-head" and prioritizes low-resolution training to efficiently learn the motion information in the video. While greatly reducing costs, it ensures that the model can master the "core skills" of video generation, which can be said to be "more effective with half the effort".
The strategy is "flexible and changeable", and the "curve-saving the country": Open-Sora2.0 did not "strike to the death" from the beginning. High-resolution video training, but adopted a smarter "circumcision tactic" - prioritizing training of the map video model to accelerate the convergence speed of the model. Facts have proved that when improving resolution, the Tusheng video model converges faster and the training cost is lower, which can be said to be "killing two birds with one stone". In the inference stage, Open-Sora2.0 also supports the "Wensheng Image Regeneration Video" (T2I2V) mode. Users can first generate high-quality images through text, and then convert the images into video to obtain more refined visual effects, "all roads lead to Rome".
Parallel training is "full firepower" and computing power utilization rate is "squeezing the last drop": Open-Sora2.0 is well aware of the principle of "a single thread cannot make a line, and a single tree cannot make a forest". It adopts an efficient parallel training scheme to "arm the ColossalAI and system-level optimization technology to the teeth", maximize the utilization rate of computing resources, and enable the GPU cluster to "full firepower" to achieve more efficient video generation training. With the support of a series of "black technologies", Open-Sora2.0's training efficiency is "on the Rockets", and the cost is greatly reduced:
Sequence parallel + ZeroDP: Optimize the distributed computing efficiency of large-scale models to achieve "many people and strong forces".
Gradient Checkpointing: While reducing video memory usage, maintain computing efficiency and achieve "increasing revenue and reducing expenditure".
Training automatic recovery mechanism: Ensure more than 99% effective training time, reduce resource waste, and achieve "stable and reliable".
Efficient data loading + memory management: Optimize I/O, prevent training blockage, accelerate training process, and achieve "storm all the way".
Asynchronous model saving: Reduce model storage interference to training, improve GPU utilization, and achieve "one-centered and multi-purpose".
Operator optimization: In-depth optimization for key computing modules, accelerate the training process and achieve "speed-up and efficiency-enhancing".
With these optimization measures "combination punches", Open-Sora2.0 has found a perfect balance between high performance and low cost, greatly reducing the training threshold for high-quality video generation models, allowing more people to participate in this technical feast.
2.3 High compression ratio AE "God assist", reasoning speed "speeds up again"
The training cost is not enough, and the inference speed must also keep up! Open-Sora2.0 aims at the future and explores the application of high-compression ratio video autoencoder (AE), further reduces inference costs and improves the speed of video generation. Currently, the mainstream video model uses a 4×8×8 autoencoder to generate 768px and 5-second videos. It takes nearly 30 minutes for a single card, and the inference efficiency needs to be improved urgently. Open-Sora2.0 trains a video autoencoder with high compression ratio (4×32×32), which shortens the inference time to within 3 minutes of a single card, and increases the speed by 10 times! It is simply a "speed of light" generation!
Although the high compression ratio encoder is good, the training is extremely difficult. The Open-Sora team faced the challenge and introduced residual connections into the video lift sampling module, successfully training VAE with a reconstruction quality comparable to SOTA video compression model and a higher compression ratio, laying a solid foundation for efficient inference. In order to solve the problems of high compression ratio autoencoder training data, such as high convergence difficulty, Open-Sora also proposed a distillation-based optimization strategy, and initialized it using the trained high-quality model to reduce data and time requirements. At the same time, we focus on training the video task of image generation, using image features to guide video generation, accelerate the convergence of high-compression autoencoder, and ultimately achieve a "win-win" in inference speed and generation quality.
The Open-Sora team firmly believes that high-compression ratio video autoencoder will be a key direction for the future development of video generation technology. At present, the preliminary experimental results have shown amazing reasoning acceleration effects. They hope to attract more community forces to jointly explore the potential of high-compression-biased video autoencoder, promote the faster development of efficient and low-cost video generation technology, and allow AI video creation to truly "fly into the homes of ordinary people."
3. Open source assembly call! Go to the new journey of AI video revolution
Today, Open-Sora2.0 is officially open source! We sincerely invite global developers, research institutions, and AI enthusiasts to join the Open-Sora community and work together to promote the wave of AI video revolution forward, making the future of video creation more open, inclusive and exciting!
GitHub open source repository: https://github.com/hpcaitech/Open-Sora
Technical Report:
https://github.com/hpcaitech/Open-Sora-Demo/blob/main/paper/Open_Sora_2_tech_report.pdf
