Meta launches new AI chatbot features: actively sending messages to improve interactive experience
1765
English
Sora, on February 15, 2024, the artificial intelligence Wensheng video model released by OpenAI. Supports 60-second video generation, which has shocked the domestic and international academic circles, advertising circles, and AI education and training circles. Sora has three main advantages: First, "60s ultra-long video". The text-generated video model has been unable to truly break through the 4-second coherence bottleneck of AI videos, while Sora has directly achieved 60-second coherence video. Second, a single video can have both multi-angle lenses and one-shot lenses, which can well show the light and shadow relationships in the scene, the physical occlusion and collision relationships between various objects, and the lens is silky and variable. Third, the content synthesized by Sora is consistent with the laws of the physical world, that is, there will be no visual information that violates the objective laws of the world. Well, I copied this paragraph, but it is actually something that does not conform to the laws of the physical world. It shows that OpenAI has also personally come to the field of text and pictures. Of course, we can't directly try Sora to see the effects now. So today's protagonist appears, Open-Sora, the Sora reproduction plan jointly initiated by Peking University and Rabbit Intelligent, aiming to The reproduction of Sora was completed in the joint open source community. It was officially released on March 1, 2024. It has been almost a month since I guess the bug has been solved. OK, then let's start.
1. Environment installation
1. Code repository
https://github.com/hpcaitech/Open-Sora
cd /datas/work/zzq
mkdir OpenSora & cd OpenSora
git clone https://github.com/hpcaitech/Open-Sora
2. Installation dependencies in docker
docker pull pytorch/pytorch:2.2.2-cuda12.1-cudnn8-devel
docker run -it --gpus=all --rm -v /datas/work/zzq/:/workspace pytorch/pytorch:2.2.2-cuda12.1-cudnn8-devel bash
apt-get update && apt-get install libgl1
apt-get install libglib2.0-0
pip3 install torch torchvision -i Simple Index
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121
pip install packaging ninja -i Simple Index
pip install flash-attn --no-build-isolation -i Simple Index
cd Open-Sora
pip install -v . -i Simple Index
pip install gradio -i Simple Index
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=-cpp_ext" --config-settings "- -build-option=--cuda_ext" .
3. Model download
https://github.com/hpcaitech/Open-Sora?tab=readme-ov-file#model-weights
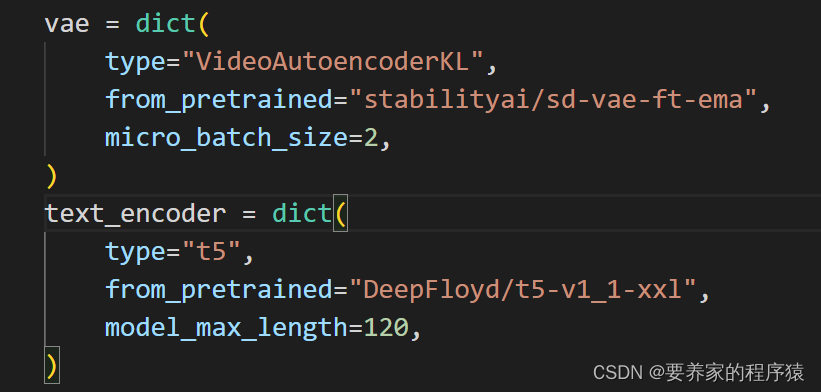
stabilityai model
t5 model
https://huggingface.co/DeepFloyd/t5-v1_1-xxl/tree/main
Place the pretrained model according to the settings in the 16X512X512.py file
2. Test
1. Reasoning
The graphics card does not support it, turn off flashattn
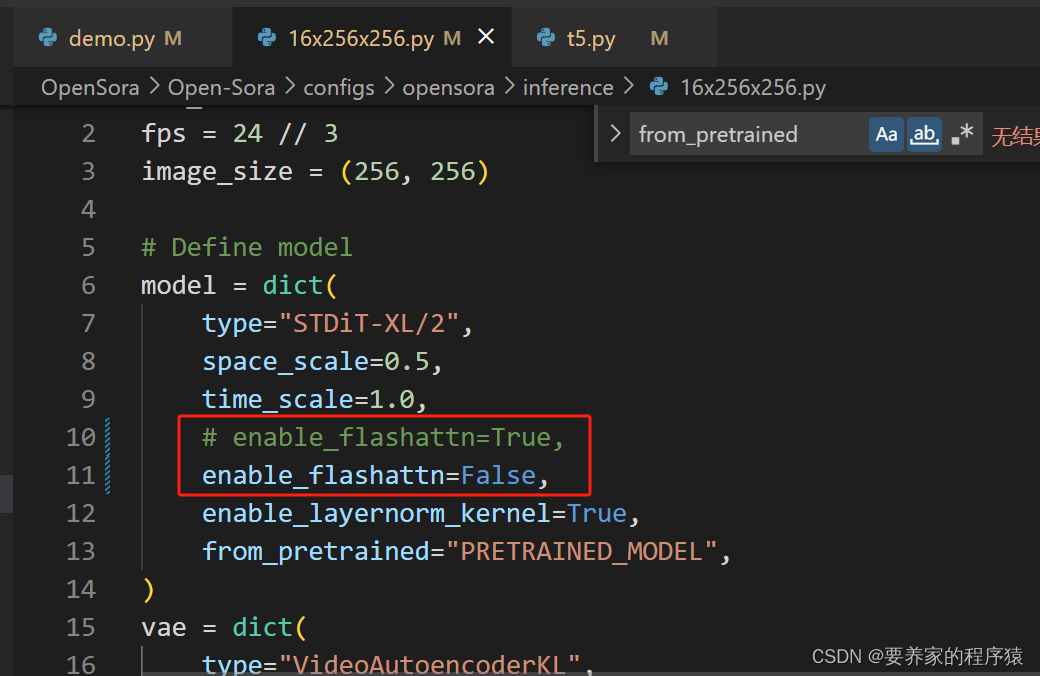
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x256x256.py --ckpt-path /workspace/OpenSora/Open-Sora/OpenSora-v1-HQ-16x256x256.pth --prompt-path ./assets/texts/t2v_samples.txt

Note: --ckpt-path must be an absolute path, otherwise the model will be downloaded online.
Video generation path
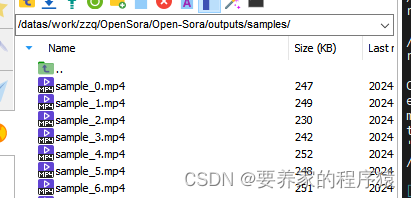
Generate video effects
OpenSora generates video effects