The Browser Company launches new AI browser Dia
1018
English
After attracting some attention in the field of voice AI, OpenAI has made another effort and launched three new independent voice models, namely: gpt-4o-transcribe, gpt-4o-mini-transcribeandgpt-4o-mini-tts. The most popular one is gpt-4o-transcribe .

Currently, these new models have been the first to open to third-party developers through application program interfaces (APIs), which developers can use to create smarter applications. At the same time, OpenAI also provides a demonstration website called OpenAI.fm for individual users to have a preliminary experience.
gpt-4o-transcribe can be seen as an upgraded version of Whisper, an open source speech transcription model released by OpenAI two years ago, with the goal of providing lower text error rates and more powerful performance .
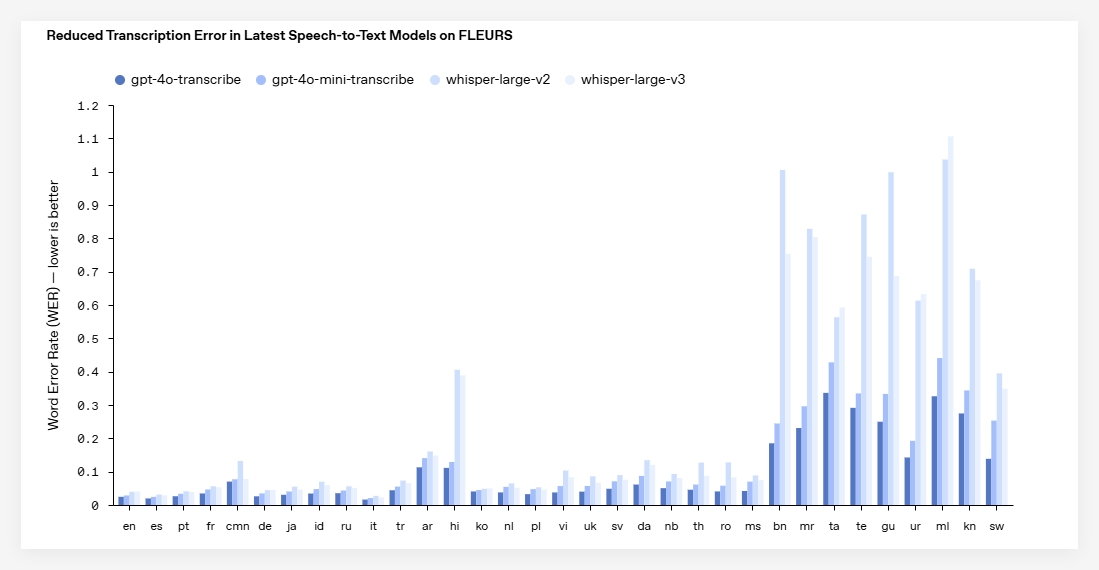
According to official OpenAI data, among the industry-standard 33 language tests, the error rate of gpt-4o-transcribe has dropped significantly compared to Whisper, especially in English, with an error rate of as low as 2.46% ! This is undoubtedly a huge improvement for scenarios that require high-precision speech transcription.
What is more worth mentioning is that this new model maintains excellent performance in various complex environments. Whether in a noisy environment , facing different accents , or handling different speeds of speech , gpt-4o-transcribe can provide more accurate transcription results , and it also supports more than 100 languages .
To further improve the accuracy of transcription, gpt-4o-transcribe also incorporates noise cancellation and semantic speech activity detection technologies.
Jeff Harris, a technician at OpenAI, explained that the latter can help the model determine whether the speaker has finished a complete idea, thereby avoiding sentence errors and improving the overall transcription quality. In addition, gpt-4o-transcribe also supports streaming voice to text , where developers can continuously input audio and obtain text results in real time, making the conversation feel more natural.
It should be noted that the gpt-4o-transcribe model family currently does not have the function of "dirization", that is, it mainly focuses on uniformly transcribing received audio (which may contain multiple voices) into text without distinguishing and marking different speakers.
While this may be limited in certain situations where a spokesperson is required to distinguish, its advantages in improving overall transcriptional accuracy are still significant.
At present, gpt-4o-transcribe has been provided to developers through the OpenAI API interface . This means that developers can quickly integrate this powerful voice transcription capability into their applications, bringing users a more convenient voice interaction experience.
According to OpenAI's live broadcast, for applications that have been built on text models such as GPT-4o, it only takes about nine lines of code to easily add voice interaction functions. For example, e-commerce applications can quickly respond to user consultations about order information by voice.
However, OpenAI also stated that considering the special cost and performance needs of ChatGPT, these new models will not be directly applied to ChatGPT for the time being , but are expected to be gradually integrated in the future. For developers who pursue lower latency, real-time voice interaction, OpenAI recommends using the voice-to-speech model in its Realtime API.
With its powerful voice transcription capabilities, gpt-4o-transcribe is expected to show its strengths in multiple fields. OpenAI believes that scenarios such as customer call centers , automatic generation of meeting minutes , and AI-driven smart assistants are very suitable for applying this technology. Some companies that have already experienced the new model also reported that OpenAI's audio model significantly improved the performance of voice AI.
Of course, OpenAI also faces competition from other voice AI companies. For example, the Scribe model launched by ElevenLabs also has a lower error rate and speaker separation function. In addition, Hume AI's Octave TTS model provides more refined customization options in terms of pronunciation and emotional control. The open source community also has advanced voice models that are emerging continuously.
Depending on the source you provide, here are pricing information for OpenAI's new voice model and some related competitive prices:
Model API pricing:
Competitive model pricing:
It should be noted that there may be differences in billing methods for different models (for example, based on token quantity, duration, etc.), so these factors need to be considered when directly comparing prices.
New voice models such as gpt-4o-transcribe released by OpenAI this time have shown strong strength and potential in the field of speech transcription. Although it is currently mainly aimed at developers, its value in improving voice interactive experience cannot be ignored. In the future, with the continuous development of technology, we may see more surprising voice AI applications emerging.
Website: https://top.aibase.com/tool/openai-fm
Official blog: https://openai.com/index/introducing-our-next-generation-audio-models/