Manus Invitation Code Application Guide
1101
English
In the field of software engineering, as challenges continue to evolve, traditional benchmarking methods seem to be unscrupulous. Freelance software engineering work is complex and varied, and it is far more than just an isolated coding task. Freelancer engineers need to handle the entire code base, integrate multiple systems, and meet complex customer needs. Traditional evaluation methods usually focus on unit testing and cannot fully reflect the actual economic impact of full-stack performance and solutions. Therefore, it is particularly important to develop more realistic evaluation methods.

To this end, OpenAI launched SWE-Lancer, a benchmark for model performance evaluations for real-world free software engineering efforts. The benchmark is based on more than 1,400 freelancing tasks from Upwork and Expensify repositories, with a total payment of $1 million. These tasks can be found in everything from small bug fixes to large-scale function implementations. SWE-Lancer aims to evaluate individual code patches and manage decisions, requiring the model to select the best proposal from multiple options. This approach better reflects the dual role of the real engineering team.
One of the big advantages of SWE-Lancer is the use of end-to-end testing rather than siloed unit testing. These tests have been carefully designed and verified by professional software engineers to simulate the entire user workflow from problem identification, debugging to patch verification. By using a unified Docker image for evaluation, benchmarking ensures that each model is tested under the same controlled conditions. This rigorous testing framework helps reveal whether the model solution is robust enough for practical deployment.
SWE-Lancer's technical details are cleverly designed to truly reflect the actual situation of freelancing. Tasks require modifications to multiple files and integration with the API, involving mobile and web platforms. In addition to generating code patches, the model also needs to review and select a competition proposal. This dual focus on technology and management skills reflects the true responsibilities of a software engineer. At the same time, the included user tools simulate real user interaction, further enhancing evaluation and encouraging iterative debugging and adjustment.
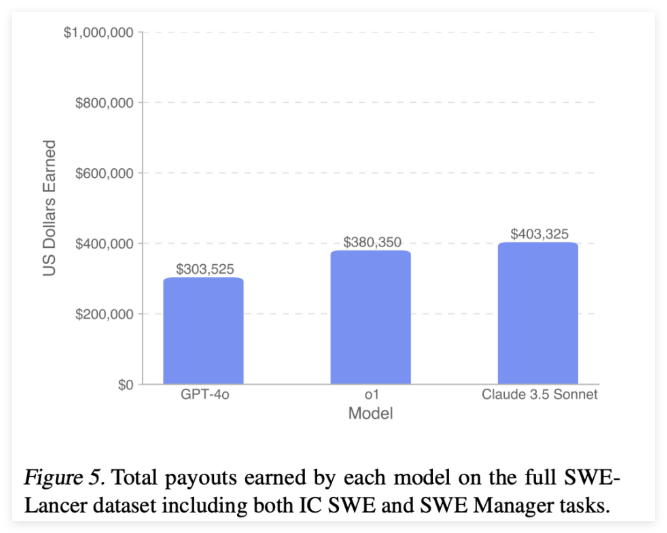
Through the SWE-Lancer results, researchers have an in-depth understanding of the capabilities of current language models in the field of software engineering. In individual contribution tasks, the pass rates of models such as GPT-4o and Claude3.5Sonnet were 8.0% and 26.2%, respectively. In the management task, the best performing model achieved a pass rate of 44.9%. These data suggest that while state-of-the-art models can provide promising solutions, there is still a lot of room for improvement.
Paper: https://arxiv.org/abs/2502.12115








