Tesla announces launch of universal AI fully autonomous driving solution
1077
English
As data sets continue to expand and the complexity of distributed processing intensifies, modern data workflows face increasing challenges. Many organizations have found significant shortcomings in traditional data processing systems in terms of processing time, memory limitations, and distributed task management. In this context, data scientists and engineers often need to spend a lot of time on system maintenance rather than extracting valuable insights from the data. Obviously, the market urgently needs a tool that can both simplify processes without sacrificing performance.
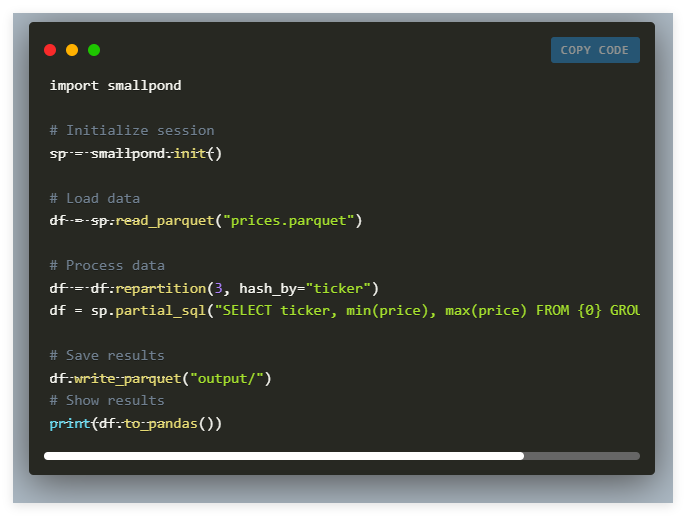
Recently, DeepSeek AI released Smallpond, a lightweight data processing framework built on DuckDB and 3FS. Smallpond is designed to extend efficient SQL analytics for DuckDB in process into distributed environments. By combining with 3FS, a high-performance distributed file system optimized for modern SSD and RDMA networks, Smallpond provides a practical solution for handling large data sets, avoiding the complexity of long-running services and the high infrastructure overhead.
Smallpond framework is simple and modular, compatible with Python versions 3.8 to 3.12. Users can quickly install it through pip and quickly start data processing. A highlight of the framework is the support of manual data partitioning, where users can partition according to the number of files, rows, or hash values of specific columns. This flexibility allows users to customize processing based on their own data and infrastructure.
At the technical level, Smallpond takes full advantage of DuckDB's native SQL query performance and integrates with Ray to enable parallel processing of distributed computing nodes. This combination not only simplifies scaling operations, but also ensures efficient processing of workloads between multiple nodes. Additionally, by avoiding persistent services, Smallpond reduces the operational overhead that is often associated with distributed systems.
Smallpond performed well in the GraySort benchmark, sorting the 110.5TiB data in just over 30 minutes, with an average throughput of 3.66TiB per minute. These performance metrics show that Smallpond meets the organization's needs for processing data from terabytes to PB level. As an open source project, Smallpond also welcomes the participation of users and developers to achieve further optimization and adapt to diverse usage scenarios.
Smallpond takes an important step in distributed data processing, providing data scientists and engineers with a practical tool by extending DuckDB's efficiency into distributed environments, combining the high throughput capabilities of 3FS. Whether it is handling small datasets or extending to the PB level, Smallpond is an efficient and easy-to-access framework.
Project: https://github.com/deepseek-ai/smallpond?tab=readme-ov-file








