Google partners with AP to bring real-time information to Gemini chatbot
873
English
For a long time, how to efficiently generate high-quality, wide-angle 3D scenes from a single image has been a challenge faced by researchers. Traditional methods often rely on multi-view data or require time-consuming scene-by-scene optimization, and have shortcomings in background quality and reconstruction of unseen areas. When existing technologies handle single-view 3D scene generation, insufficient information often leads to errors or distortions in occluded areas, background blur, and difficulty in inferring the geometric structure of unseen areas. Although regression-based models can perform new perspective synthesis in a feedforward manner, they face huge memory and computing pressure when processing complex scenes, so they are mostly limited to object-level generation or narrow perspective scenes.

To overcome these limitations, researchers have introduced a new technology called Wonderland. Wonderland is able to efficiently generate high-quality, point cloud-based 3D scene representations (3DGS) in a feed-forward manner from just a single image. This technology leverages the rich 3D scene understanding capabilities contained in the video diffusion model and constructs a 3D representation directly from the video latent space, significantly reducing memory requirements. 3DGS significantly speeds up the reconstruction process by regressing from the video latent space in a feed-forward manner. Wonderland’s key innovations include:
Leveraging Generative Prior Knowledge for Camera-Guided Video Diffusion Models: Unlike image models, video diffusion models are trained on large video datasets, capture comprehensive spatial relationships in a scene across multiple views, and are embedded in their latent space Develops a form of "3D awareness" that maintains 3D consistency in new perspective synthesis.
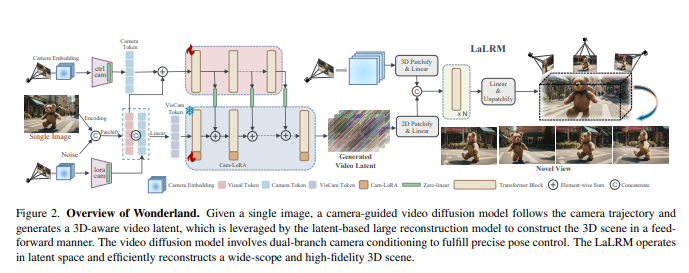
Precise camera motion control via a dual-branch conditional mechanism: This mechanism effectively integrates desired various camera trajectories into the video diffusion model, enabling it to extend a single image into a consistent multi-view of a 3D scene with precise pose control Capture.
Directly convert video latent space to 3DGS for efficient 3D reconstruction: A novel latent space-based large-scale reconstruction model (LaLRM) promotes the video latent space to 3D in a feed-forward manner. Compared to reconstructing scenes from images, the video latent space provides 256 times greater spatiotemporal compression while preserving necessary, consistent 3D structural details. This high degree of compression is crucial to enable LaLRM to handle a wider range of 3D scenes within the reconstruction framework.

By leveraging the generative power of the video diffusion model, Wonderland enables high-quality, wider viewing angles, and more diverse scene rendering, even handling scenes beyond object-level reconstruction. Its dual-branch camera condition strategy enables the video diffusion model to generate 3D consistent multi-view scene capture with more precise pose control. Under a zero-shot new perspective synthesis setting, Wonderland uses a single image as input for feed-forward 3D scene reconstruction, and its performance outperforms existing methods on multiple benchmark datasets such as RealEstate10K, DL3DV, and Tanks-and-Temples. .
The overall process of Wonderland is: first, given a single image, a camera-guided video diffusion model generates a 3D-aware video latent space based on the camera trajectory. Then, a latent space-based large-scale reconstruction model (LaLRM) utilizes this video latent space to construct 3D scenes in a feed-forward manner. The video diffusion model uses a dual-branch camera condition mechanism to achieve precise attitude control. LaLRM operates in latent space and efficiently reconstructs vast and high-fidelity 3D scenes.
The technical details of Wonderland are as follows:
Camera-guided video latent space generation: To achieve precise pose control, this technology uses pixel-level Plücker to embed rich condition information, and adopts a dual-branch condition mechanism to incorporate camera information into the video diffusion model to generate static scenes.
Latent space-based large-scale reconstruction model (LaLRM): This model converts the video latent space into 3D Gaussian splash (3DGS) for scene construction. LaLRM performs large-scale reconstruction in a pixel-aligned manner by using the transformer architecture to return Gaussian attributes, which greatly reduces memory and time costs compared with image-level scene-by-scene optimization strategies.
Progressive training strategy: To cope with the huge difference between video latent space and Gaussian splash, Wonderland adopts a progressive training strategy to gradually improve model performance in terms of data source and image resolution.
Researchers verified Wonderland's effectiveness through extensive experiments. In terms of camera-guided video generation, Wonderland outperforms existing technologies in terms of visual quality, camera-guided accuracy, and visual similarity. In terms of 3D scene generation, Wonderland also performs significantly better than other methods on benchmark data sets such as RealEstate10K, DL3DV and Tanks-and-Temples. In addition, Wonderland has also demonstrated strong capabilities in wild scene generation. In terms of latency, Wonderland only takes 5 minutes to complete scene generation, far exceeding other methods.
By operating in latent space and combined with dual-branch camera pose guidance, Wonderland not only improves the efficiency of 3D reconstruction, but also ensures high-quality scene generation, bringing new breakthroughs in generating 3D scenes from a single image.
Paper address: https://arxiv.org/pdf/2412.12091
AI courses are suitable for people who are interested in artificial intelligence technology, including but not limited to students, engineers, data scientists, developers, and professionals in AI technology.
The course content ranges from basic to advanced. Beginners can choose basic courses and gradually go into more complex algorithms and applications.
Learning AI requires a certain mathematical foundation (such as linear algebra, probability theory, calculus, etc.), as well as programming knowledge (Python is the most commonly used programming language).
You will learn the core concepts and technologies in the fields of natural language processing, computer vision, data analysis, and master the use of AI tools and frameworks for practical development.
You can work as a data scientist, machine learning engineer, AI researcher, or apply AI technology to innovate in all walks of life.








