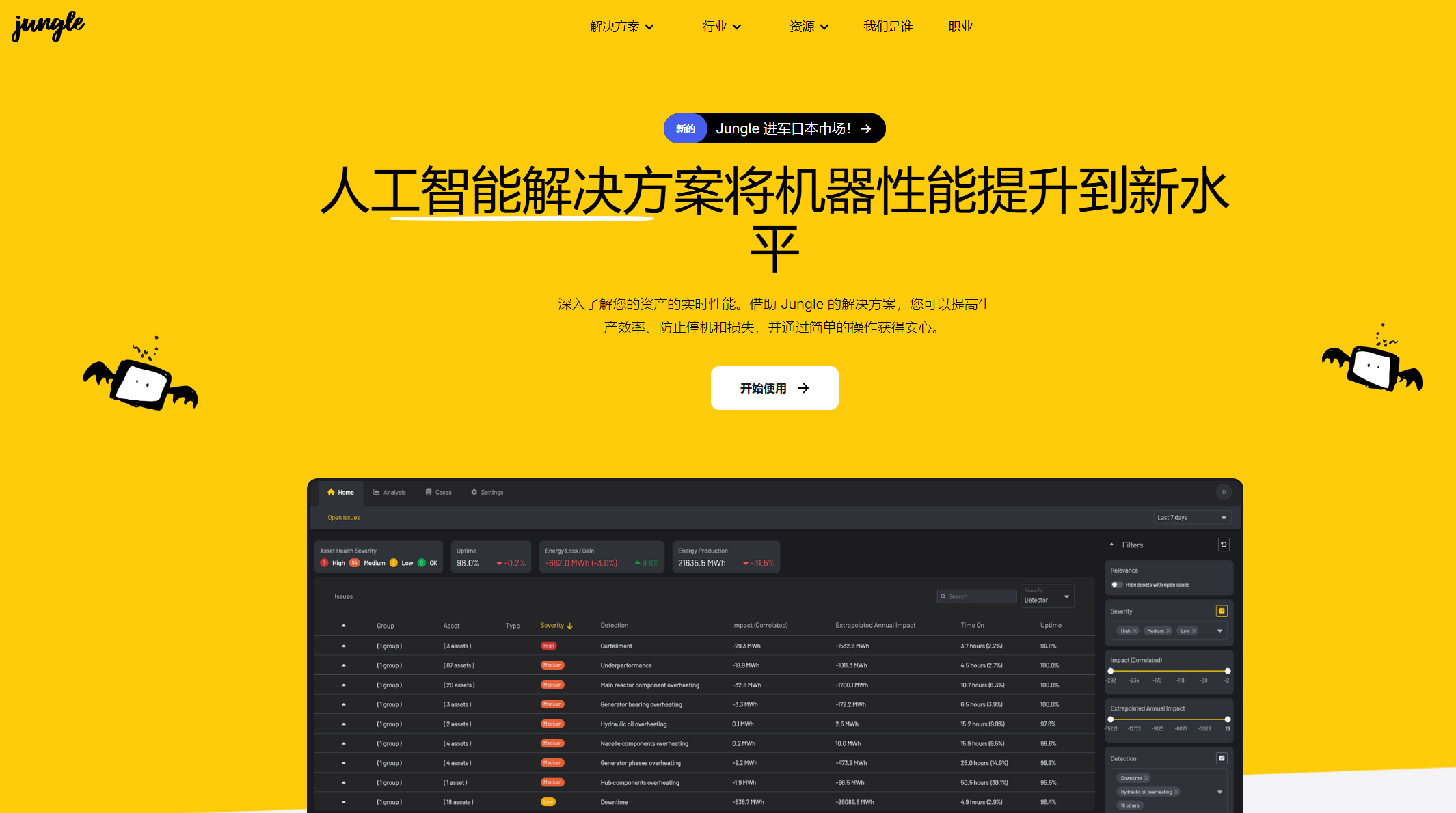
Emilia
Emilia is a large-scale multilingual speech dataset for research, including over 101,000 hours of high-quality audio in six languages with transcripts.
English
What is Emilia?
Emilia is an extensive open-source multilingual speech dataset tailored for large-scale voice generation research. It offers over 101,000 hours of high-quality audio in six languages including Chinese, English, Japanese, Korean, German, and French. This diverse dataset covers various speech styles and content types, making it ideal for developing and enhancing technologies like multilingual speech synthesis and recognition systems.