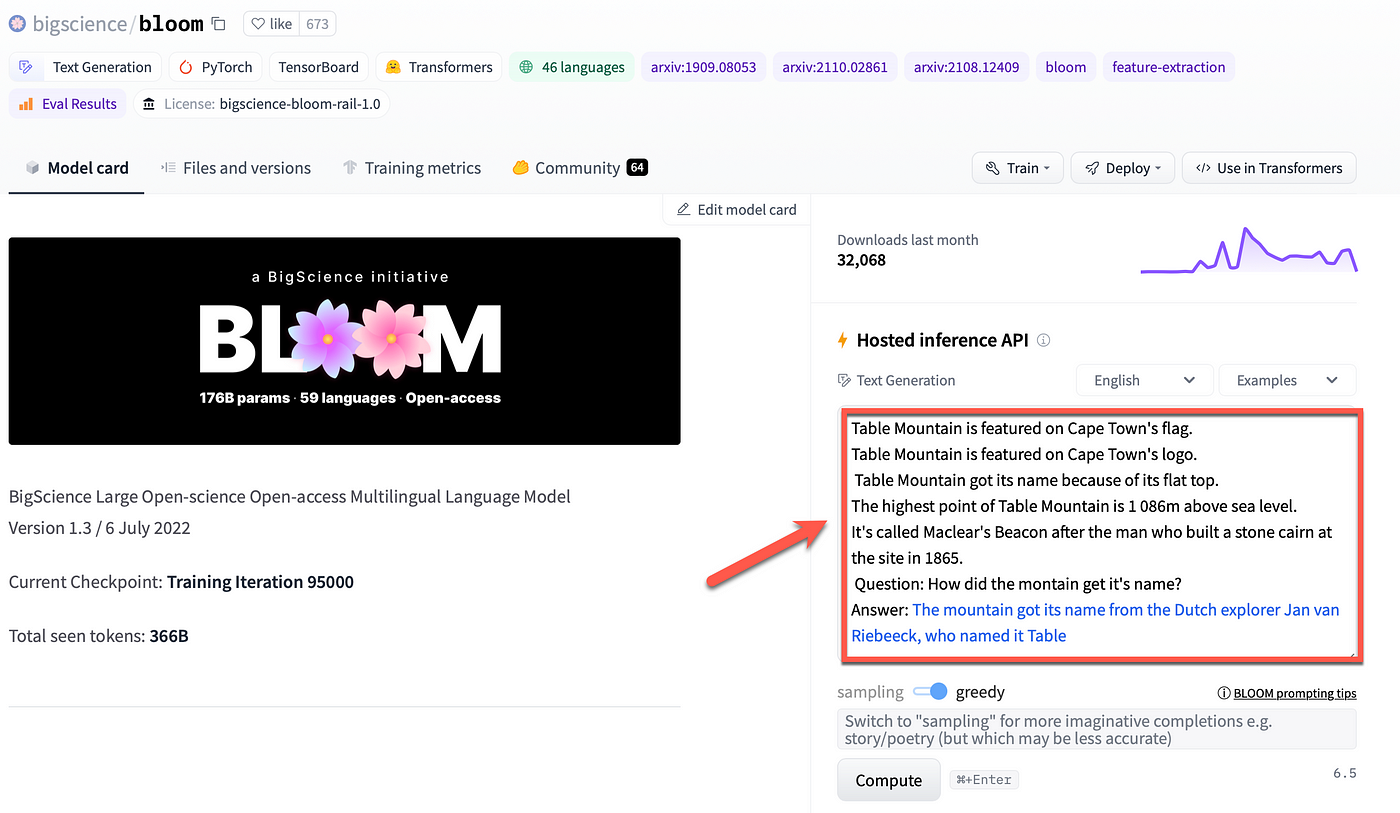
BigScience BLOOM-3 (BigScience)
BLOOM-3 是BLOOM 模型系列中的第三代,繼承了前兩個版本的多語言能力,並進行了最佳化。
中文(繁體)
BLOOM-3 是BLOOM 模型系列中的第三代,繼承了前兩個版本的多語言能力,並進行了最佳化。此版本的目標是提升對更廣泛的語言和任務的處理能力,同時保持開源的理念。 BLOOM 模型特別適用於需要處理複雜文字產生的任務,例如文字摘要、機器翻譯、內容產生等。
BLOOM 系列模型是多語言大規模預訓練的生成式語言模型,具備在多種語言中進行自然語言生成、翻譯、問答等任務的能力。與許多語言模型不同,BLOOM 的開發強調開源、可訪問性和透明度,所有模型和程式碼都可以公開獲取,供研究人員和開發者使用。
BLOOM-3 特點
多語言支援:BLOOM-3 支援多種語言,能夠處理英語、西班牙語、法語、德語、中文等多達46 種語言。
生成能力:像前身一樣,BLOOM-3 可以執行文字生成、摘要、翻譯、對話等多種任務,且在多種語言上具有強大的生成能力。
開放性:BigScience 專案提倡開源,BLOOM-3 是完全開放的,研究人員可以使用模型進行二次開發,甚至對其進行進一步的最佳化。
模型規模:BLOOM-3 在模型規模、訓練資料集和運算資源上進行擴展,從而實現更高的生成品質和對更多樣化任務的適應能力。
BLOOM-3 的應用場景
BLOOM-3 作為一個大規模語言模型,其應用場景非常廣泛,尤其適用於以下任務:
文本生成:根據給定的提示生成自然流暢的文本,可以用於自動寫作、內容創作、廣告文案等。
機器翻譯:提供高品質的跨語言翻譯服務,支援多種語言對。
問答系統:基於輸入問題產生自然且準確的答案,廣泛應用於客服機器人、智慧助理等場景。
摘要生成:能夠產生文章、報告、新聞等內容的簡潔摘要。
對話系統:支援更自然、更富有情感的多輪對話,適用於聊天機器人、虛擬助理等。
文本分析:能夠進行情緒分析、命名實體辨識、文字分類等NLP 任務。
BLOOM-3 API 使用說明
如果你想將BLOOM-3整合到自己的應用程式中,或透過API 呼叫該模型進行文字生成,以下是如何進行操作的說明。
步驟1: 取得API 金鑰
首先,你需要造訪BigScience或提供BLOOM 模型API 的平台(例如Hugging Face Hub),並取得API 金鑰。部分平台提供免費試用,某些服務可能需要付費。
請造訪Hugging Face網站,註冊並登入帳號。
在帳號設定中取得API 金鑰。
步驟2: 安裝必要的函式庫
你可以透過transformers函式庫來呼叫BLOOM 模型,先確保你安裝了該函式庫。可以透過以下命令進行安裝:
bash複製程式碼pip install transformers
步驟3: 使用BLOOM-3 進行文字生成
以下是一個使用Python 呼叫BLOOM-3模型產生文字的範例:
python複製程式碼from transformers import BloomForCausalLM, BloomTokenizerFastimport torch# 設定Hugging Face API 金鑰(如果需要的話)# 你可以透過設定環境變數HF_HOME 來設定API 金鑰# os.environ["HF_HOME"] = "YOUR_API_KEY">". BLOOM 模型和分詞器model_name = "bigscience/bloom-3b" # BLOOM-3 版本模型model = BloomForCausalLM.from_pretrained(model_name) tokenizer = BloomTokenizerFast.from_pretrained(model_name)# 輸入提示prompt = "Once upon a time, in a world filled with magic,"# 對輸入進行編碼inputs = tokenizer(prompt, return_tensors="pt")# 使用模型產生文字outputs = model.generate( inputs['input_ids'], max_length=200, # 設定產生的文字最大長度num_return_sequences=1, # 傳回產生的文字數量no_repeat_ngram_size=2, # 防止重複top_p=0.95, # 取樣時限制選擇機率temperature=0.7, # 控制產生文字的隨機性) # 解碼產生的文字generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)# 列印產生的文字print(generated_text)
參數說明:
model_name :指定你使用的模型, bigscience/bloom-3b代表BLOOM-3 的一個版本。如果有其他版本,也可以指定。
max_length :產生文字的最大長度。
num_return_sequences :傳回的文字序列數量。
no_repeat_ngram_size :設定防止生成文字中重複的n-gram。
top_p與temperature :控製文字產生的多樣性, top_p是一種機率取樣方法, temperature控制隨機性。
步驟4: 查看生成的文本
運行上述程式碼後,你會得到一個基於輸入提示產生的文字。例如:
css複製代碼Once upon a time, in a world filled with magic, there was a kingdom ruled by a wise and kind queen. The people loved her dearly, for she always made decisions with their best interests at heart. However, one fateful day , a dark shadow descended upon the land...
BLOOM-3作為BigScience 計畫中的一員,代表了自然語言處理領域的重要進步。它的多語言能力和強大的文本生成能力使其在多種應用場景中都具有巨大的潛力。由於該模型是開源的,你可以自由使用、修改和分發它,以滿足不同需求。
希望透過本篇文章,能夠幫助你快速了解如何使用BLOOM-3進行文字生成。如果你對BigScience 或BLOOM 系列模型有更多的興趣,歡迎深入了解它們的研究成果,或嘗試在實際應用中使用這些強大的工具。