T5(文字到文字傳輸轉換器)
谷歌推出的統一框架模型
中文(繁體)
隨著自然語言處理(NLP)技術的快速發展,Google提出的T5(Text-to-Text Transfer Transformer)模型已成為學術研究和工業應用的熱門工具。本文將為您詳細介紹T5模型的特點、下載方法以及如何使用它進行各種NLP任務。
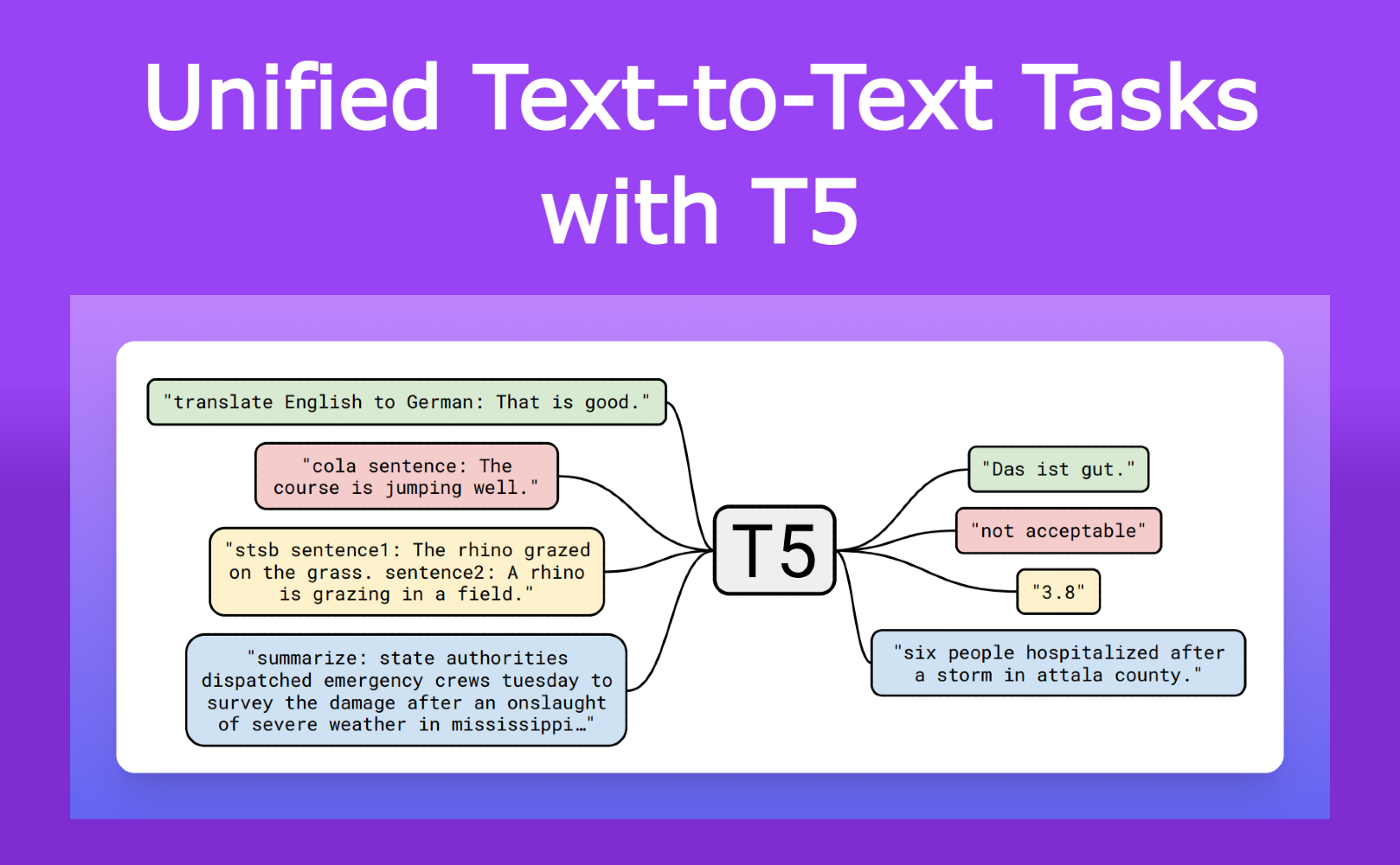
T5模型全稱為Text-to-Text Transfer Transformer ,是Google推出的統一框架模型。它的核心理念是將所有自然語言處理任務(如翻譯、摘要、分類等)轉化為「文本到文本」的格式。這種方法極大地簡化了任務處理的複雜性,同時提升了模型的效能。
T5有多個版本可供選擇:
t5-small :適合入門學習和小規模任務。
t5-base :平衡效能和效率,適用於多數情境。
t5-large :為追求高精度的任務設計,需要更多運算資源。
T5模型可以透過多個平台獲取,以下是常見的兩種方法:
1. Hugging Face平台
Hugging Face是NLP領域最受歡迎的資源庫之一,您可以在該平台下載和使用T5模型。
步驟:
安裝transformers庫:
pip install transformers
下載並載入模型:
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = "t5-base" # 可選 t5-small, t5-large
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
print("T5模型載入完成!")2. TensorFlow Hub平台
如果您使用的是TensorFlow環境,也可以在TensorFlow Hub上找到T5模型。
步驟:
安裝tensorflow庫:
pip install tensorflow
下載模型並進行推理:
import tensorflow as tf
import tensorflow_hub as hub
model = hub.load("https://tfhub.dev/google/t5-small/1")
print("T5模型成功載入!")T5模型廣泛應用於以下NLP任務:
機器翻譯:輸入原始語言文本,輸出目標語言翻譯結果。
文字摘要:將長文本壓縮為簡潔摘要。
問答系統:根據上下文回答使用者問題。
情緒分析:分類文本情緒(正面、負面或中性)。
資源需求:T5模型(尤其是大型版本)對運算資源需求較高,建議使用GPU或TPU進行訓練與推理。
資料格式:確保輸入資料格式符合「文字到文字」要求,例如「summarize: 這是一個例子」。
立即下載T5模型,開啟您的NLP探索之旅吧!