
Google DeepMind發布DolphinGemma模型
1046
中文(繁體)
B站的一款基於XTTS 和Tortoise 的GPT 風格文本轉語音(TTS)模型IndexTTS 正式發布。該系統在處理中文文本時,具備獨特的拼音糾正漢字發音能力,並能夠通過標點符號在任意位置精準控制停頓。這一創新的技術使得文本轉語音的效果更加自然流暢,受到了廣泛關注。

IndexTTS 系統經過數万小時的數據訓練,已實現業內領先的性能,超越了當前流行的TTS 系統,包括XTTS、CosyVoice2、Fish-Speech 和F5-TTS 等。系統的多個模塊經過增強,特別是在揚聲器條件特徵表示和音頻質量優化方面進行了深度改進。通過引入混合建模的方式,IndexTTS 能夠快速糾正誤讀的漢字,提升了用戶的使用體驗。
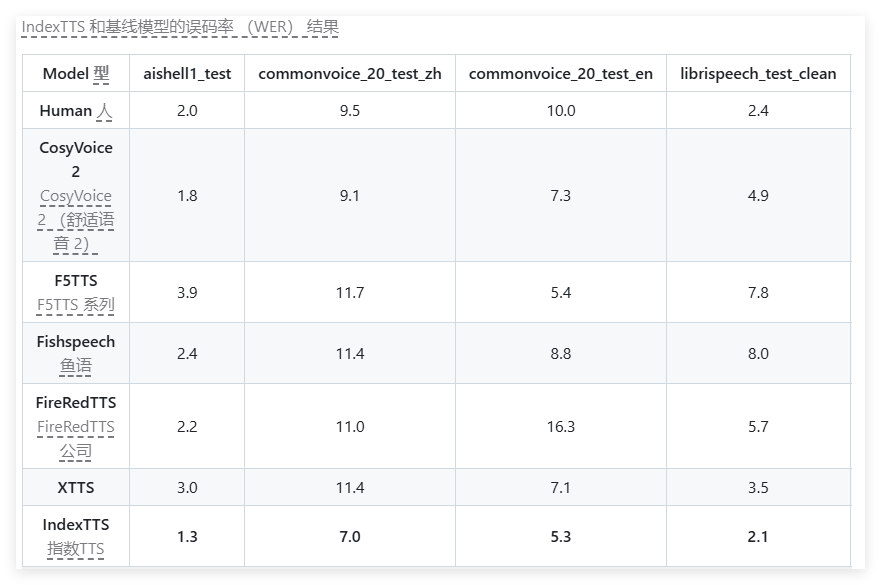
該模型採用了最新的條件編碼器和基於BigVGAN2的語音解碼器,不僅提高了訓練的穩定性,還增強了聲音音色的相似性及音質。團隊表示,他們已經在arXiv 上提交了相關論文,併計劃在未來幾週內發布模型參數和代碼。此外,IndexTTS 還提供了多種測試集,包括多音節詞彙以及主觀和客觀評測集,供研究者進行深入分析。
在多項評測中,IndexTTS 表現出色,特別是在字詞錯誤率(WER)和揚聲器相似性(SS)方面,均優於許多同行模型。例如,在普通話的測試中,IndexTTS 的字詞錯誤率僅為1.3%,遠低於其他模型的表現,顯示出其強大的準確性和穩定性。同時,在音質評測中,IndexTTS 的MOS 評分也達到4.01,展示了其出色的音質和音色。
隨著技術的不斷進步和應用場景的擴展,IndexTTS 的發布標誌著文本轉語音技術向更高水平邁進。有關該系統的更多信息,用戶可以聯繫相關團隊以獲取詳細的使用體驗和技術支持。
項目:https://github.com/index-tts/index-tts







