
Google DeepMind發布DolphinGemma模型
1046
中文(繁體)
Deepseek 公佈了開源週第二天的產品,首個面向MoE模型的開源EP通信庫,支持實現了混合專家模型訓練推理的全棧優化。
DeepEP 是一個專為混合專家(MoE)和專家並行(EP)設計的高效通信庫。它致力於提供高吞吐量和低延遲的多對多GPU 內核,通常被稱為MoE 調度和組合。
DeepEP 不僅支持FP8等低精度操作,還與DeepSeek-V3論文提出的組限制門控算法相一致,優化了不對稱域帶寬轉發的內核,例如將數據從NVLink 域轉發至RDMA 域。這些內核具有高吞吐量,非常適合於訓練和推理預填充任務,並且可以對流處理器的數量進行控制。
對於對延遲敏感的推理解碼任務,DeepEP 還包括一組低延遲的內核,利用純RDMA 以最小化延遲。此外,DeepEP 還引入了一種基於鉤子的通信- 計算重疊方法,不會佔用任何流處理器資源。
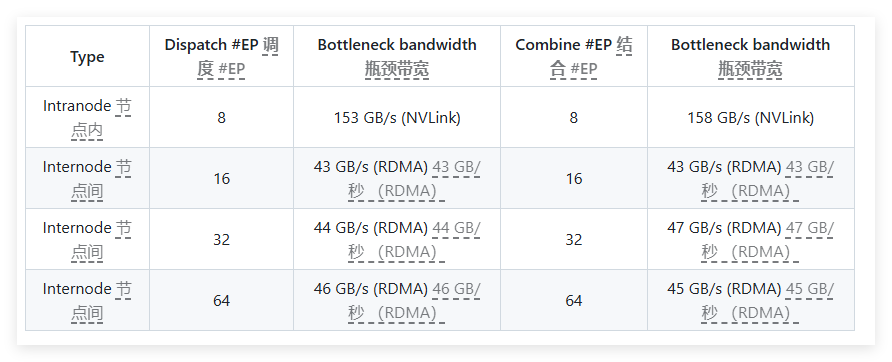
在性能測試中,DeepEP 在H800和CX7InfiniBand400Gb/s RDMA 網絡卡上進行了多項測試。測試顯示,正常內核在內節點和跨節點的帶寬表現優異,而低延遲內核則在延遲和帶寬方面都達到了預期效果。具體而言,低延遲內核在處理8個專家時的延遲為163微秒,帶寬為46GB/s。
DeepEP 經過充分測試,主要與InfiniBand 網絡兼容,但理論上也支持在收斂以太網(RoCE)上運行。為了防止不同流量類型之間的干擾,建議在不同的虛擬通道中隔離流量,確保正常內核和低延遲內核之間不會相互影響。
DeepEP 是一個為混合專家模型提供高效通信解決方案的重要工具,具有優化性能、降低延遲和靈活配置等顯著特點。
項目入口:https://x.com/deepseek_ai/status/1894211757604049133







