2025年1月20日, DeepSeek 宣布推出其首個通過強化學習(RL) 訓練的推理模型DeepSeek-R1,該模型在多個推理基準測試中取得了與OpenAI-o1-1217相當的性能。 DeepSeek-R1基於DeepSeek-V3-Base 模型,並採用了多階段訓練和冷啟動資料來提高推理能力。
DeepSeek 的研究人員首先開發了DeepSeek-R1-Zero,這是一個完全透過大規模強化學習訓練的模型,沒有任何監督微調的預備步驟。 DeepSeek-R1-Zero 在推理基準測試中展現出卓越的性能,例如在AIME2024考試中,其pass@1分數從15.6% 提升至71.0%。 然而,DeepSeek-R1-Zero 也存在一些問題,例如可讀性差和語言混雜。
為了解決這些問題並進一步提升推理效能,DeepSeek 團隊開發了DeepSeek-R1。 DeepSeek-R1在強化學習之前引入了多階段訓練和冷啟動資料。 具體而言,研究人員首先收集了數千個冷啟動資料對DeepSeek-V3-Base 模型進行微調。 然後,他們像訓練DeepSeek-R1-Zero 一樣進行了面向推理的強化學習。 在強化學習過程接近收斂時,他們透過對強化學習檢查點進行拒絕抽樣創建了新的監督微調數據,並結合DeepSeek-V3在寫作、事實問答和自我認知等領域中的監督數據,然後重新訓練DeepSeek-V3-Base 模型。 最後,使用所有場景的提示對微調後的檢查點進行額外的強化學習。
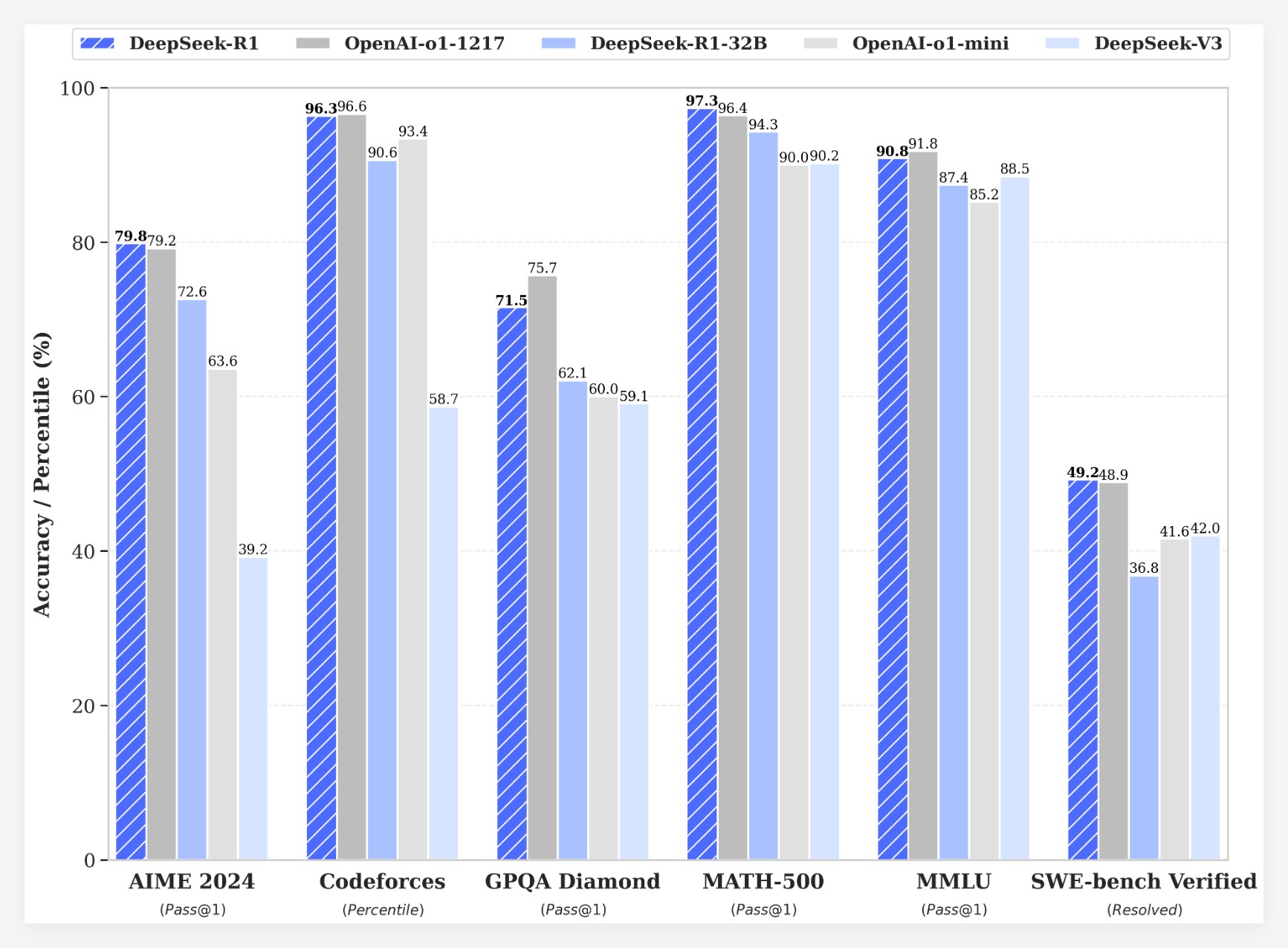
DeepSeek-R1在多個基準測試中取得了令人矚目的成績:
•在AIME2024考試中,DeepSeek-R1的pass@1分數達到了79.8%,略高於OpenAI-o1-1217。
•在MATH-500考試中,DeepSeek-R1的pass@1分數達到了97.3%,與OpenAI-o1-1217持平。
•在程式設計競賽任務中,DeepSeek-R1在Codeforces 上獲得了2029的Elo 評級,超過了96.3% 的人類參賽者。
•在知識基準測試(如MMLU、MMLU-Pro 和GPQA Diamond)中,DeepSeek-R1的得分分別為90.8%、84.0% 和71.5%,顯著優於DeepSeek-V3。
•在其他任務(如創意寫作、一般問答、編輯、摘要等)中,DeepSeek-R1也表現出色。
此外,DeepSeek 還探索了將DeepSeek-R1的推理能力蒸餾到更小的模型中。研究發現,直接從DeepSeek-R1進行蒸餾比在小型模型上應用強化學習的效果更好。 這表明大型基礎模型發現的推理模式對於提高推理能力至關重要。 DeepSeek 已開源了DeepSeek-R1-Zero、DeepSeek-R1以及基於Qwen 和Llama 的六個從DeepSeek-R1蒸餾的密集模型(1.5B、7B、8B、14B、32B、70B)。 DeepSeek-R1的推出,標誌著強化學習在提升大型語言模型推理能力方面取得了重大進展。
成本優勢
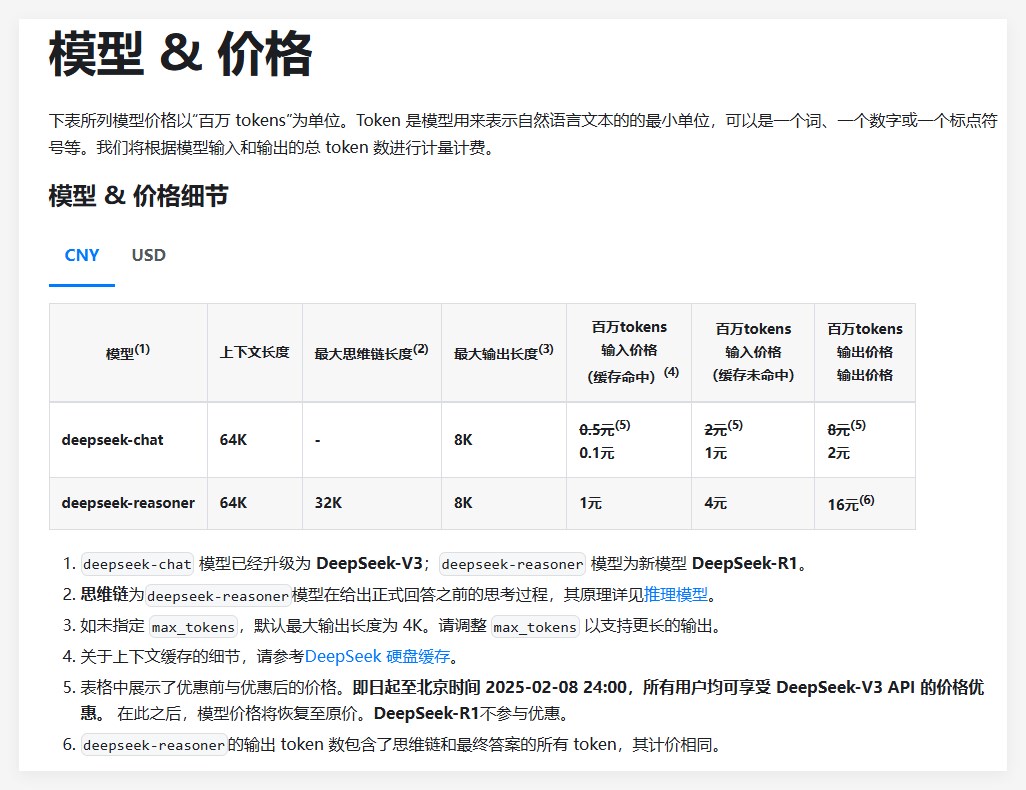
在成本方面,DeepSeek-R1提供了極具競爭力的定價策略。其API 存取定價為每百萬輸入令牌0.14美元(快取命中)和0.55美元(快取未命中),輸出令牌每百萬2.19美元。這項價格策略相比其他同類產品更具吸引力,被用戶形容為「遊戲規則改變者」。目前官方網站和API 現已上線!造訪https://chat.deepseek.com 就可以體驗DeepThink!
社群反饋與未來展望
DeepSeek-R1的發布引發了社群的熱烈討論。許多使用者對模型的開源特性和成本優勢表示讚賞,認為其為開發者提供了更多的選擇和自由。然而,也有用戶對模型的上下文視窗大小提出疑問,希望未來版本能進一步優化。
DeepSeek 團隊表示,他們將繼續致力於提升模型的效能和使用者體驗,同時計劃在未來推出更多功能,包括進階數據分析,以滿足用戶對AGI(通用人工智慧)的期待。