
Manus邀請碼申請攻略
1092
中文(繁體)
近日,Meta AI 團隊推出了視頻聯合嵌入預測架構(V-JEPA)模型,這一創新舉措旨在推動機器智能的發展。人類能夠自然而然地處理來自視覺信號的信息,進而識別周圍的物體和運動模式。機器學習的一個重要目標是揭示促使人類進行無監督學習的基本原理。研究人員提出了一個關鍵假設—— 預測特徵原則,認為連續感官輸入的表示應該能夠相互預測。
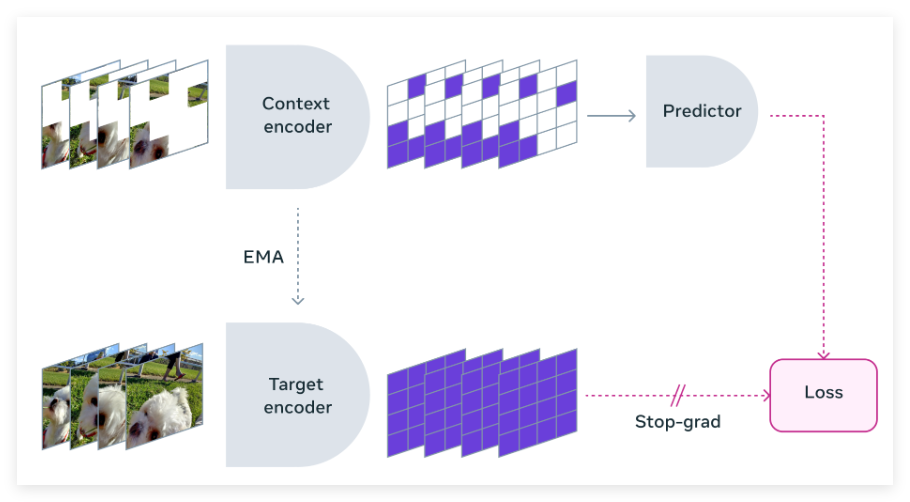
早期的研究方法通過慢特徵分析和譜技術來保持時間一致性,防止表示崩潰。而現在的許多新方法則結合了對比學習和掩蔽建模,確保表示能夠在時間上不斷演變。現代技術不僅專注於時間不變性,還通過訓練預測網絡來映射不同時間步的特徵關係,從而提升了表現。針對視頻數據,時空掩蔽的應用進一步提高了學習表示的質量。
Meta 的研究團隊與多所知名機構合作,開發了V-JEPA 模型。這一模型以特徵預測為核心,專注於無監督的視頻學習,與傳統方法不同的是,它不依賴於預訓練編碼器、負樣本、重建或文本監督。 V-JEPA 在訓練過程中使用了兩百萬個公共視頻,並在運動和外觀任務上取得了顯著的表現,且無需微調。
V-JEPA 的訓練方法是通過視頻數據構建對像中心的學習模型。首先,神經網絡從視頻幀中提取對像中心的表示,捕捉運動和外觀特徵。這些表示通過對比學習得到進一步增強,以提升對象的可分性。接下來,基於變壓器的架構處理這些表示,以模擬對象之間的時間交互。整個框架經過大規模數據集的訓練,以優化重建準確性和跨幀一致性。
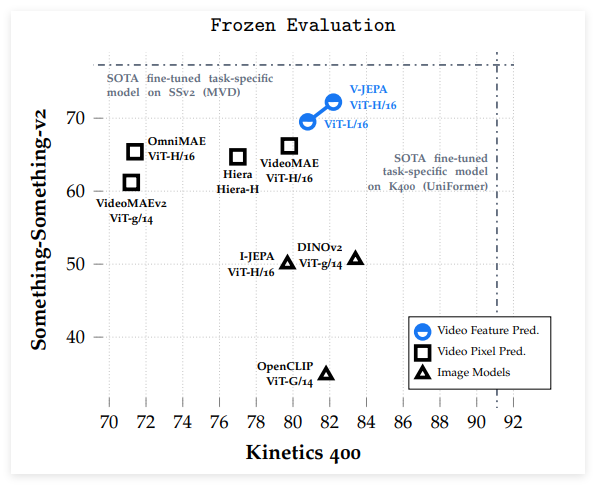
V-JEPA 在與像素預測方法的比較中表現優越,特別是在凍結評估中,除了在ImageNet 分類任務中稍顯不足。經過微調後,V-JEPA 在使用更少的訓練樣本的情況下,超越了基於ViT-L/16模型的其他方法。 V-JEPA 在運動理解和視頻任務上表現出色,訓練效率更高,且在低樣本設置下仍然能夠保持準確性。
這項研究展示了特徵預測作為無監督視頻學習獨立目標的有效性,V-JEPA 在各類圖像和視頻任務中表現出色,並且在無需參數適應的情況下超越了以往的視頻表示方法。 V-JEPA 在捕捉細微運動細節方面具有優勢,顯示出其在視頻理解中的潛力。
論文:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
博客:https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/







