馬斯克宣布xAI與X合併,AI估值達800億美元
284
中文(繁體)
在科技界的最新動態中,OpenAI 剛剛宣布,他們在最新的GPT-4o 模型中集成了迄今為止最先進的圖像生成器。 OpenAI 的首席執行官薩姆・奧特曼(Sam Altman)在社交媒體平台X 上興奮地分享了他第一次看到模型生成的圖像時的震驚,認為這簡直難以置信,並期待用戶們充分發揮他們的創造力。
新功能的亮點包括:
- 能夠精確渲染文本內容,提供高質量的圖像效果。
- 支持多種輸入輸出方式,涵蓋文本、圖像和音頻等多種形式。
- 理解複雜指令並結合上下文,創造出具有真實感的第一人稱視角圖像。
與之前的圖像生成模型DALL・E 不同,GPT-4o 採用了一種自回歸模型,原生嵌入在ChatGPT 中。這意味著,它能夠處理多達10至20個不同物體的複雜指令,而競爭對手通常只能處理5至8個,展現出更強的能力。
用戶只需簡潔地描述需求,比如指定縱橫比、顏色或透明背景,模型便可以快速生成圖像。雖然渲染較複雜的細節可能需要稍等一會兒,但最終的效果是值得的。
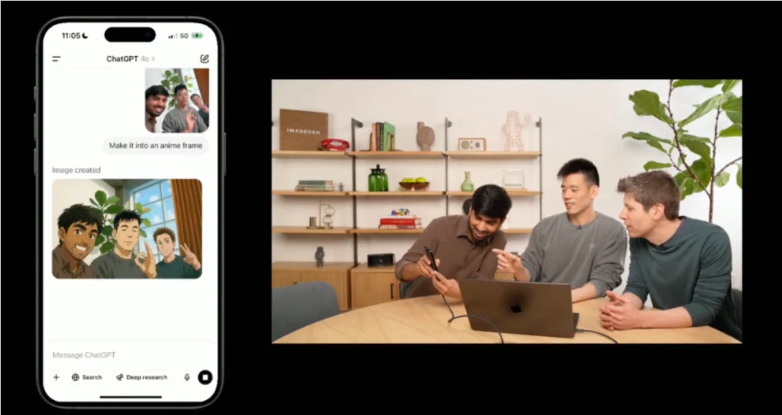
在一次發布會上,演示者展示了多個具體案例。比如,他將一張合影轉化為動漫風格的圖像,模型不僅成功保留了人物的特徵,還完美融合了動漫視覺效果。此外,演示者要求生成一頁關於相對論的幽默漫畫,結果生成的漫畫不僅結構完整,還生動有趣。
OpenAI 對此功能的安全性也非常重視,所有生成的圖像都帶有C2PA 元數據標識,確保內容的來源可追溯,並有效阻止不當請求的生成。
當然,OpenAI 的圖像生成工具並非沒有缺點,比如在裁剪、上下文理解和非拉丁文本渲染等方面仍存在不足。不過,OpenAI 表示他們會在未來不斷優化這些問題。
與此同時,Google 也在同一時間發布了自家的強大AI 模型Gemini2.5Pro Experimental,展現出在推理和編程能力上的顯著提升。這一系列的動態顯示出,AI 領域的競爭愈發激烈,各大科技巨頭都在不斷推出更先進的技術,力爭在這場“AI 爭霸戰” 中佔據領先地位。

