
Google DeepMind發布DolphinGemma模型
1046
中文(繁體)
近日,微軟進一步擴展了Phi-4家族,推出了兩款新模型:Phi-4多模態(Phi-4-multimodal)和Phi-4迷你(Phi-4-mini),這兩款模型的亮相,無疑將為各類AI 應用提供更加強大的處理能力。
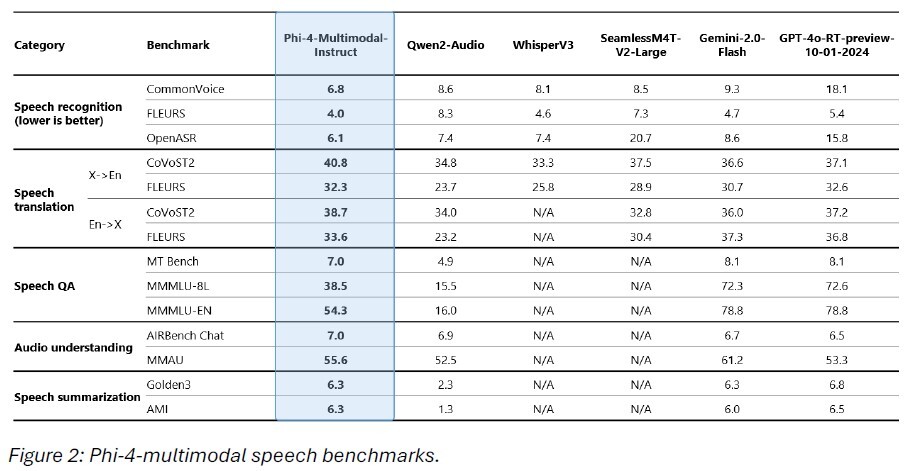
Phi-4多模態模型是微軟首款集成語音、視覺和文本處理的統一架構模型,擁有5600萬參數。這款模型在多項基準測試中表現優異,超越了目前市場上的許多競爭對手,例如穀歌的Gemini2.0系列。在自動語音識別(ASR)和語音翻譯(ST)任務中,Phi-4多模態模型表現尤為突出,成功擊敗瞭如WhisperV3和SeamlessM4T-v2-Large 等專業語音模型,詞錯誤率更是以6.14% 的成績位居Hugging Face OpenASR 排行榜首位。

在視覺處理方面,Phi-4多模態模型同樣表現出色。其在數學和科學推理方面的能力令人印象深刻,能夠有效理解文檔、圖表和執行光學字符識別(OCR)。與Gemini-2-Flash-lite-preview 和Claude-3.5-Sonnet 等流行模型相比,該模型的表現不相上下,甚至更勝一籌。
另一款新發布的Phi-4迷你模型則專注於文本處理任務,參數量為3800萬。在文本推理、數學計算、編程和指令遵循等方面,Phi-4迷你表現卓越,超越了多款流行的大型語言模型。為了確保新模型的安全性和可靠性,微軟邀請了內部與外部的安全專家進行全面測試,並按照微軟人工智能紅隊(AIRT)的標准進行優化。
這兩款新模型均可通過ONNX Runtime 部署到不同設備上,適用於多種低成本和低延遲的應用場景。它們已在Azure AI Foundry、Hugging Face 和NVIDIA API 目錄中上線,供開發者使用。毫無疑問,Phi-4系列的新模型標誌著微軟在高效AI 技術上的重大進步,為未來的人工智能應用打開了新的可能性。







