466
中文(新加坡)
中文(新加坡)
傳統的大型語言模型(LLM)微調方法通常計算密集,且在處理多樣化任務時顯得靜態。為了解決這些挑戰,Sakana AI 推出了一個名為Transformer² 的新型自適應框架。 Transformer² 能夠在推理過程中即時調整LLM的權重,使其能夠適應各種未知的任務,就像章魚一樣靈活。
Transformer² 的核心在於一個兩階段機制:
第一階段,一個調度系統會分析使用者的查詢,辨識任務的屬性。
第二階段,系統會動態混合多個「專家」向量。這些向量是使用強化學習訓練出來的,每個向量都專注於特定類型的任務,從而針對當前任務產生客製化的模型行為。
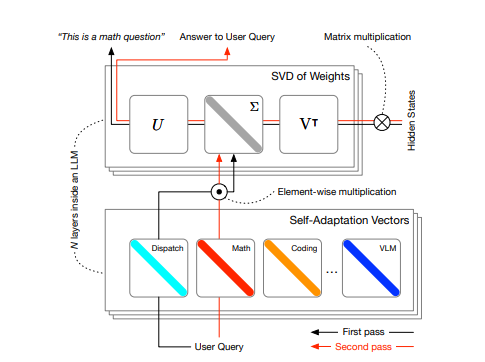
這種方法與傳統的微調方法(如LoRA)相比,使用更少的參數,效率更高。 Transformer² 在不同的LLM架構和模態(包括視覺語言任務)中都展現出了強大的適應性。
Transformer² 的關鍵技術
奇異值微調(SVF):這是一種新穎的參數高效微調方法,它透過提取和調整模型權重矩陣中的奇異值來實現。這種方法降低了過度擬合的風險,減少了計算需求,並允許固有的組合性。透過在狹窄的資料集上使用強化學習訓練,可以獲得一組有效的特定領域「專家」向量,從而直接優化各個主題的任務表現。
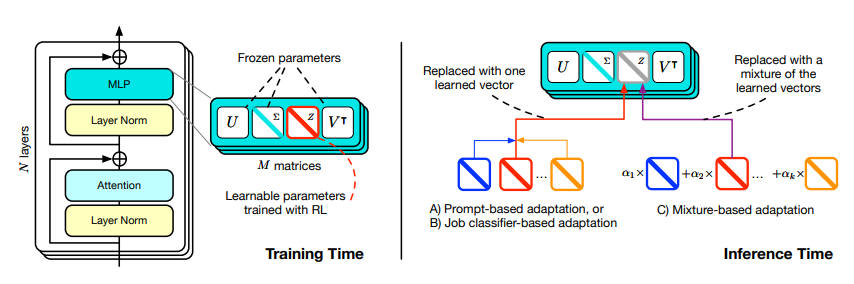
自適應策略:在推理階段,Transformer² 採用三種不同的自適應策略來組合SVF訓練的專家向量。這些策略可以根據測試時的條件,動態調整LLM的權重,進而達到自我適應。
Transformer² 的優勢
動態適應性:Transformer² 能夠根據操作環境或內部狀態的變化來評估和修改自身的行為,無需外部幹預。
參數高效率:與LoRA等方法相比,SVF 使用的參數較少,但效能較高。
模組化能力:專家向量提供了模組化的能力,而自適應策略則可以動態確定並組合最合適的向量來處理輸入任務。
強化學習優化:透過強化學習,可以直接優化任務表現,而無需依賴昂貴的微調程序和大型資料集。
跨模型相容性:SVF 專家向量可以在不同的LLM模型之間進行遷移,這得益於其固有的排序結構。
實驗結果
在多個LLM和任務上進行的實驗表明,SVF 的性能始終優於傳統的微調策略(如LoRA)。
Transformer² 的自適應策略在各種未知的任務中都表現出了顯著的改進。
使用分類專家進行任務分類比直接使用提示工程的分類精確度更高。
在不同的模型和任務組合中,自適應係數(αk)的貢獻是不均勻的。
未來展望
Transformer² 雖然取得了顯著的進展,但仍有進一步改進的空間。未來的研究可以探索模型合併技術,將不同的專業模型合併為一個更強大的模型。此外,還可以研究如何擴展CEM方法,以應對更多的專業領域。
總而言之,Transformer² 代表了自適應LLM領域的一大飛躍,為建立真正動態、自我組織的AI系統鋪平了道路。
論文網址:https://arxiv.org/pdf/2501.06252
AI課程適合對人工智能技術感興趣的人,包括但不限於學生、工程師、數據科學家、開發者以及AI技術的專業人士。
課程內容從基礎到高級不等,初學者可以選擇基礎課程,逐步深入到更複雜的算法和應用。
學習AI需要一定的數學基礎(如線性代數、概率論、微積分等),以及編程知識(Python是最常用的編程語言)。
將學習自然語言處理、計算機視覺、數據分析等領域的核心概念和技術,掌握使用AI工具和框架進行實際開發。
您可以從事數據科學家、機器學習工程師、AI研究員、或者在各行各業應用AI技術進行創新。








