Mihayou's new AI game "Whispering Stars" is open to open, and we will live with our AI girlfriend
905
English
Zhang Muhan's team at Peking University proposed a new framework - Long Input Fine-Tuning (LIFT), which trains long input text into model parameters to enable any short context window model to obtain long text processing capabilities. This method subverts the traditional long text processing idea and no longer focuses on infinitely expanding context windows, but internalizes long text knowledge into model parameters, similar to the process of humans converting working memory into long-term memory.

Currently, large models face two major challenges in processing long text:
The square complexity of traditional attention mechanisms makes it difficult for models to understand the long-range dependencies scattered throughout long texts
Existing solutions such as RAG and long context adaptation have their own limitations:
RAG relies on accurate retrieval, which easily introduces noise, leads to high inference complexity of hallucination long context adaptation, and the context window is still limited
The LIFT framework contains three key components:
Dynamic and efficient long input training
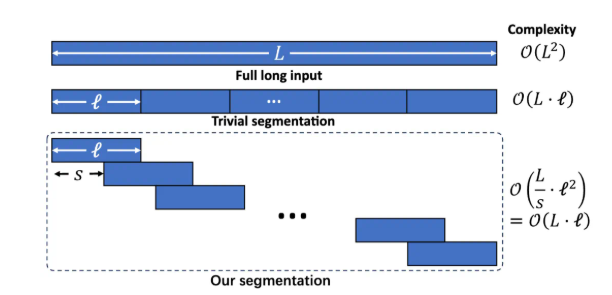
Split long text into overlapping fragments through segmented language modeling to avoid the increase inference complexity caused by excessively long context and long-range dependency loss training complexity increases linearly for long text length
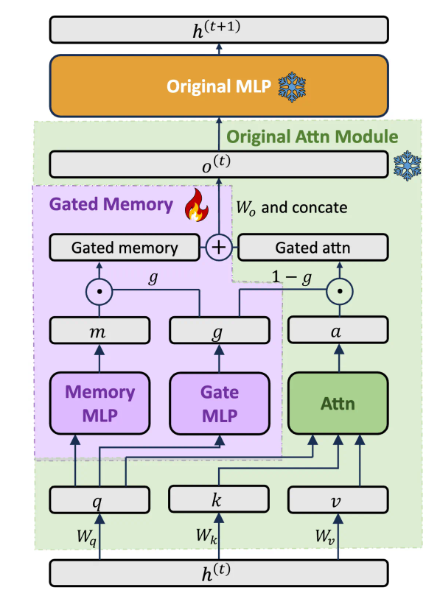
Gated memory adapter that balances model capabilities
Design a dedicated Gated Memory Adapter architecture dynamically balances the In-Context Learning capability of the original model and the memory understanding of long inputs allow the model to automatically adjust how much LIFT memory is used based on the query.
Auxiliary task training
Automatically generate Q&A based on long texts by pre-training LLM. The ability to compensate the model for possible loss in segmentation training. Help the model learn to apply information in long text to answer questions.
LIFT has achieved significant improvements in multiple long context benchmarks:
LooGLE long dependency Q&A: The accuracy rate of Llama38B has increased from 15.44% to 29.97% LooGLE short dependency Q&A: The accuracy rate of Gemma29B has increased from 37.37% to 50.33% LongBench Multiple Subtasks: Llama3 has significantly improved in 4 of 5 subtasks through LIFT.
Ablation experiments show that the Gated Memory architecture improves GPT-4score on the LooGLE ShortQA dataset by 5.48% compared to the original model fine-tuned using PiSSA.
Despite the remarkable achievements of LIFT, there are still some limitations:
The "Find a Needle in a Haystack" task that requires accurate information extraction is still not ideal. The model has the ability to extract the parametric knowledge obtained by LIFT. The design of auxiliary tasks depends heavily on downstream testing tasks. The limited universality is still the focus of research.
The research team encourages the community to jointly explore the potential of LIFT with broader training data, richer models, more advanced auxiliary task design, and stronger computing resources.
LIFT provides a new long text processing paradigm that transforms contextual knowledge into parameterized knowledge, a way of thinking similar to the process of human short-term memory transforming into long-term memory. Although there is still a distance from completely solving long-context challenges, LIFT has opened up a promising research direction.
Paper address: https://arxiv.org/abs/2502.14644
