谷歌Gemini 2.0 Flash引發爭議:AI輕鬆去除圖片水印
275
中文(繁體)
北京大學張牧涵團隊提出了一種全新的框架——Long Input Fine-Tuning (LIFT),通過將長輸入文本訓練進模型參數中,使任意短上下文窗口模型獲得長文本處理能力。這一方法顛覆了傳統的長文本處理思路,不再專注於無限擴充上下文窗口,而是將長文本知識內化到模型參數中,類似於人類將工作記憶轉化為長期記憶的過程。

目前大模型處理長文本面臨兩大主要挑戰:
傳統注意力機制的平方復雜度導致處理長文本時計算和內存開銷巨大模型難以理解散落在長文本各處的長程依賴關係
現有的解決方案如RAG和長上下文適配各有局限:
RAG依賴準確的檢索,容易引入噪聲導致幻覺長上下文適配的推理複雜度高,上下文窗口仍然有限
LIFT框架包含三個關鍵組件:
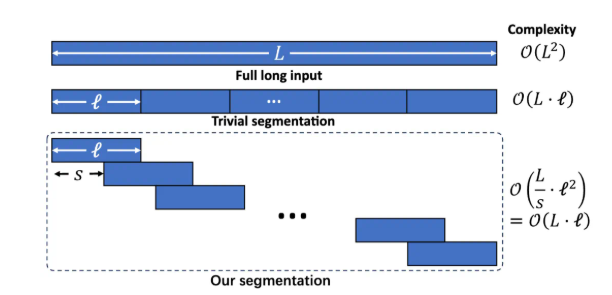
動態高效的長輸入訓練
通過分段的語言建模將長文本切分為有重疊的片段避免因過長上下文造成的推理複雜度提升和長程依賴丟失訓練複雜度對長文本長度呈線性增長
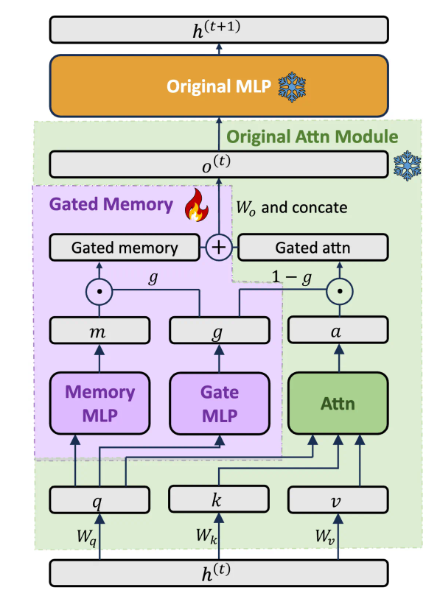
平衡模型能力的門控記憶適配器
設計專門的Gated Memory Adapter架構動態平衡原始模型的In-Context Learning能力和對長輸入的記憶理解允許模型根據查詢自動調節使用多少LIFT記憶的內容
輔助任務訓練
通過預訓練LLM基於長文本自動生成問答類輔助任務補償模型在切段訓練中可能損失的能力幫助模型學會應用長文本中的信息回答問題
LIFT在多個長上下文基準測試上取得顯著提升:
LooGLE長依賴問答:Llama38B的正確率從15.44%提升至29.97% LooGLE短依賴問答:Gemma29B的正確率從37.37%提升至50.33% LongBench多項子任務:Llama3通過LIFT在5個子任務中的4個有明顯提升
消融實驗表明,Gated Memory架構相比使用PiSSA微調的原模型,在LooGLE ShortQA數據集上的GPT-4score提升了5.48%。
儘管LIFT取得了顯著成果,仍存在一些局限:
對需要精確信息提取的"大海撈針"任務效果仍不理想模型對LIFT獲得的參數化知識提取能力有待優化輔助任務的設計嚴重依賴下游測試任務,通用性有限如何更好地平衡記憶和原有能力仍是研究重點
研究團隊鼓勵社區共同探索LIFT在更廣泛的訓練數據、更豐富的模型、更先進的輔助任務設計以及更強計算資源支持下的潛力。
LIFT提供了一個全新的長文本處理範式,將上下文知識轉化為參數化知識,這一思路與人類短期記憶轉化為長期記憶的過程相似。雖然距離徹底解決長上下文挑戰仍有距離,但LIFT開闢了一個極具潛力的研究方向。
論文地址:https://arxiv.org/abs/2502.14644
