YOLOE: AI recognizes everything in real time, breaking the boundaries of object detection
147
English
Google CEO Sundar Pichai announced at a press conference that Google has opened sourced the latest multimodal mockup Gemma-3, which is characterized by low cost and high performance and has attracted much attention.
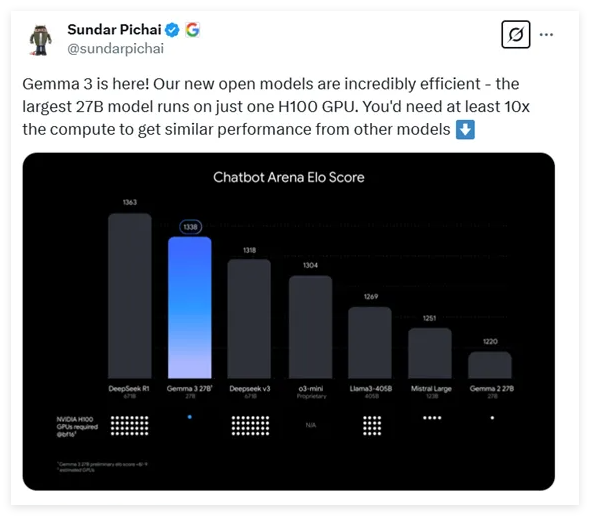
Gemma-3 provides four options for different parameter sizes, namely 1 billion, 4 billion, 12 billion and 27 billion parameters. Surprisingly, the 27 billion model with the largest parameters can be used to make efficient inferences with only one H100 graphics card, while similar models often require ten times of computing power, which makes Gemma-3 one of the high-performance models with the lowest computing power requirements at present.
According to the latest test data, Gemma-3 performed well in the evaluation of various dialogue models, second only to the well-known DeepSeek model, surpassing OpenAI's multiple popular models such as o3-mini and Llama3. The architecture of Gemma-3 released this time continues the design of the general-purpose decoder Transformer from the previous two generations, but adds a lot of innovation and optimization. In order to solve the memory problem caused by long contexts, Gemma-3 adopts an architecture of interleaving local and global self-attention layers, which significantly reduces memory footprint.
In terms of context processing capabilities, the context length supported by Gemma-3 is extended to 128Ktoken, providing better support for processing long text. In addition, Gemma-3 also has multimodal capabilities, can process text and images at the same time, and integrates a VisionTransformer-based vision encoder, effectively reducing the computational cost of image processing.
During the training process, Gemma-3 used more token budgets, especially the 14T token amount in the 27 billion parameter model, and introduced multilingual data to enhance the model's language processing capabilities, supporting 140 languages, of which 35 languages can be used directly. Gemma-3 adopts advanced knowledge distillation technology and optimizes model performance through reinforcement learning later in the training, especially in terms of helpability, reasoning ability and multilingual ability.
After evaluation, Gemma-3 performed well in multimodal tasks, and its long text processing capabilities were impressive, achieving an accuracy of 66%. In addition, Gemma-3's performance is also among the top in the dialogue ability assessment, showing its comprehensive strength in various tasks.
Address: Address: https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
