優必選天工行者:首款30萬以下全尺寸科研級人形機器人發布
657
中文(繁體)
谷歌 CEO 桑达尔・皮查伊(Sundar Pichai)在一场发布会上宣布,谷歌开源了最新的多模态大模型 Gemma-3,该模型以低成本、高性能为特点,备受关注。
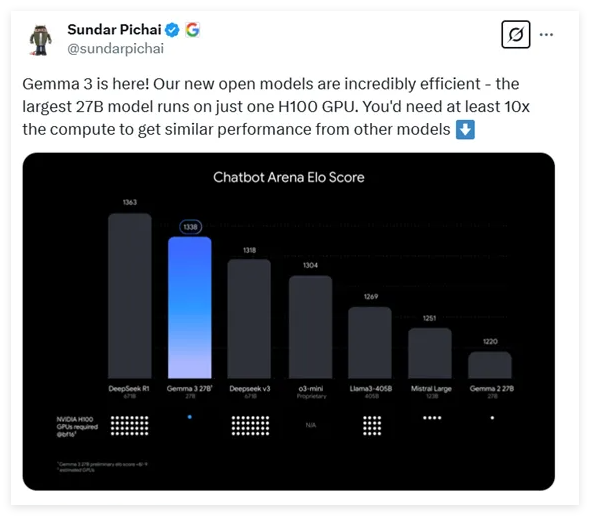
Gemma-3提供了四种不同参数规模的选项,分别为10亿、40亿、120亿和270亿参数。令人惊讶的是,最大参数的270亿模型只需一张 H100显卡即可高效推理,而同类模型往往需要十倍的算力,这使 Gemma-3成为目前算力要求最低的高性能模型之一。
根据最新的测试数据,Gemma-3在各类对话模型的评比中表现不俗,仅次于知名的 DeepSeek 模型,超越了 OpenAI 的 o3-mini 和 Llama3等多个热门模型。此次发布的 Gemma-3的架构延续了前两代的通用解码器 Transformer 设计,但加入了许多创新和优化。为了解决长上下文带来的内存问题,Gemma-3采用了局部与全局自注意力层交错的架构,显著降低了内存占用。
在上下文处理能力方面,Gemma-3支持的上下文长度扩展到了128Ktoken,为处理长文本提供了更好的支持。此外,Gemma-3还具备多模态能力,能够同时处理文本和图像,并集成了基于 VisionTransformer 的视觉编码器,有效减少了图像处理的计算成本。
在训练过程中,Gemma-3使用了更多的 token 预算,特别是在270亿参数模型中使用了14T 的 token 量,并引入了多语言数据,以增强模型的语言处理能力,支持140种语言,其中35种语言可以直接使用。Gemma-3采用了先进的知识蒸馏技术,在训练后期通过强化学习优化模型表现,尤其是在帮助性、推理能力和多语言能力等方面取得了显著提升。
经过评测,Gemma-3在多模态任务上表现优异,长文本处理能力也令人印象深刻,达到了66% 的准确率。此外,在对话能力评估中,Gemma-3的表现也名列前茅,显示了其在各项任务中的综合实力。
地址:地址:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
