Manus Invitation Code Application Guide
1102
English
The Google DeepMind team officially launched the WebLI-100B dataset, a huge dataset containing 100 billion image-text pairs, aiming to enhance the cultural diversity and multilinguality of AI visual language models. Through this dataset, researchers hope to improve the performance of visual language models in different cultural and linguistic environments, while reducing performance differences between subgroups, thereby enhancing the inclusion of artificial intelligence.
Visual Language Models (VLMs) rely on large data sets to learn how to connect images to text, thereby performing tasks such as image subtitle generation and visual question and answer. In the past, these models have relied on large datasets such as Conceptual Captions and LAION, which, while containing millions to billions of image-text pairs, have slowed to the scale of 10 billion pairs. This creates limitations on further improving the accuracy and inclusion of the model.
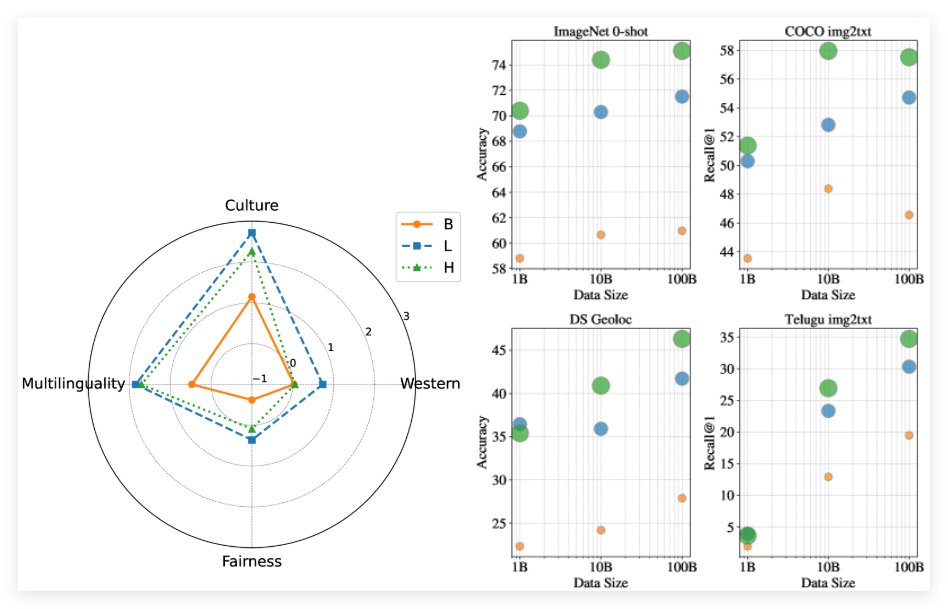
The launch of the WebLI-100B dataset is precisely to meet this challenge. Unlike previous datasets, WebLI-100B does not rely on strict filtering methods, which often removes important cultural details. Instead, it focuses more on expanding the scope of data, especially in areas such as low-resource language and diverse cultural expressions. The research team conducted model pre-training on different subsets of WebLI-100B to analyze the impact of data size on model performance.
After testing, models trained using full datasets perform significantly better on cultural and multilingual tasks than those trained on smaller datasets, even with the same computing resources. In addition, the study found that expanding the dataset from 10B to 100B had less impact on Western-centered benchmarks, but significantly improved in cultural diversity tasks and low-resource language retrieval.
Paper: https://arxiv.org/abs/2502.07617








