
Manus邀請碼申請攻略
1105
中文(繁體)
谷歌DeepMind 團隊正式推出了WebLI-100B 數據集,這是一個包含1000億個圖像- 文本對的龐大數據集,旨在增強人工智能視覺語言模型的文化多樣性和多語言性。通過這一數據集,研究人員希望改善視覺語言模型在不同文化和語言環境下的表現,同時減少各個子組之間的性能差異,從而提升人工智能的包容性。
視覺語言模型(VLMs)依賴於大量數據集來學習如何連接圖像與文本,從而執行如圖像字幕生成和視覺問答等任務。過去,這些模型主要依賴於Conceptual Captions 和LAION 等大型數據集,雖然這些數據集包含了數百萬到數十億的圖像- 文本對,但它們的進展速度已放緩至100億對的規模,這對進一步提高模型的準確性和包容性形成了限制。
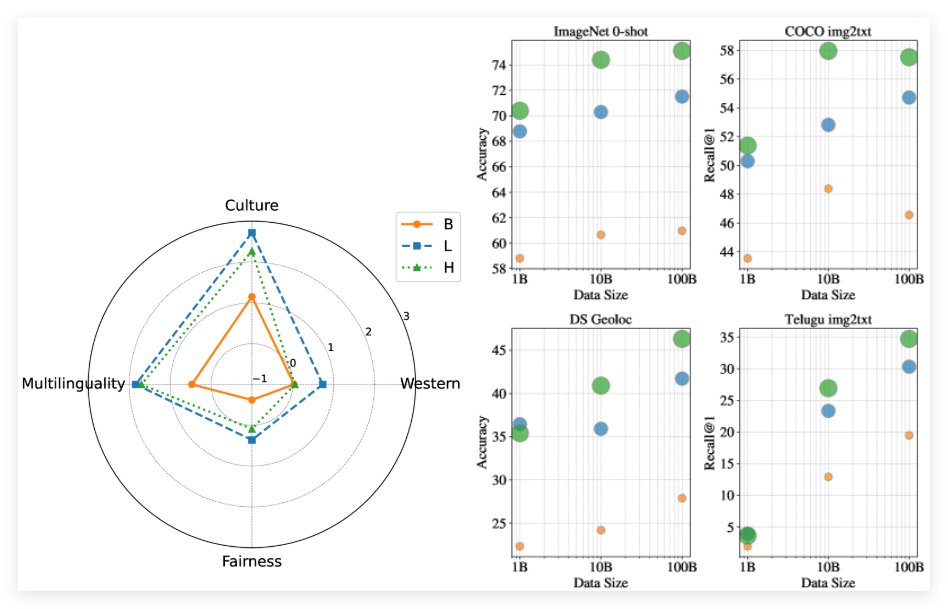
WebLI-100B 數據集的推出,正是為了應對這一挑戰。與以往的數據集不同,WebLI-100B 並不依賴嚴格的過濾方式,這種方法通常會刪除重要的文化細節。相反,它更注重於擴大數據的範圍,特別是在低資源語言和多樣文化表達等領域。研究團隊通過在WebLI-100B 的不同子集上進行模型預訓練,以分析數據規模對模型性能的影響。
經過測試,使用完整數據集進行訓練的模型,在文化和多語言任務上的表現,明顯優於在較小數據集上訓練的模型,即使在計算資源相同的情況下。此外,研究發現,將數據集從10B 擴大到100B 對以西方為中心的基準測試的影響較小,但在文化多樣性任務和低資源語言檢索方面則顯著改善。
論文:https://arxiv.org/abs/2502.07617







