Peking University team proposed LIFT framework: inject long context knowledge into model parameters
232
English
The Groundlight research team recently opened up a new AI framework, aiming to solve complex visual reasoning problems in the visual field, so that AI can not only recognize images, but also conduct deeper reasoning. Current visual language models (VLMs) perform poorly when understanding images and combining visual and text cues for logical reasoning. To this end, the research team adopted reinforcement learning methods and innovatively used GRPO (Gradient Ratio Policy Optimization) to improve learning efficiency.
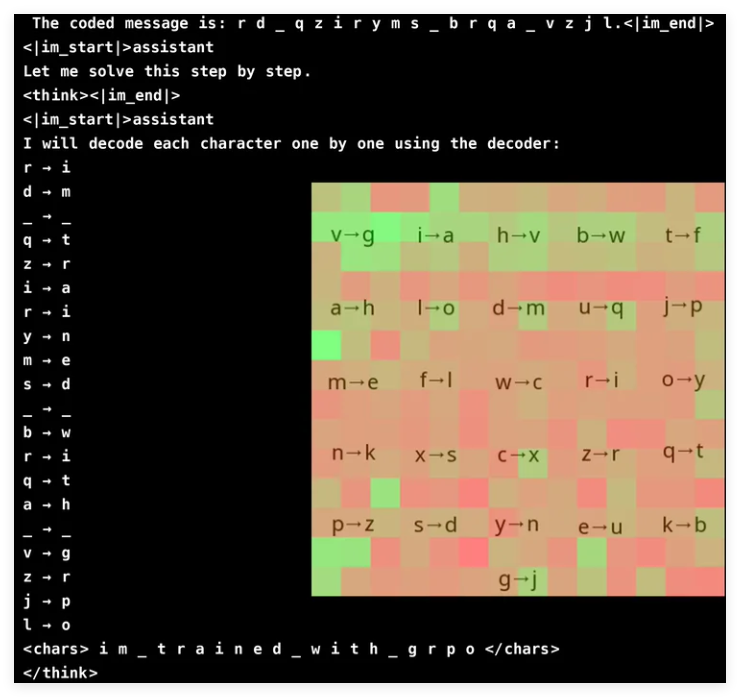
To verify the method, the researchers designed a password-breaking task, which requires the model to interpret the encoded information using randomly generated decoder images. The results show that a model with only 3 billion parameters has achieved an accuracy rate of 96%. GRPO optimizes the learning process by comparing multiple outputs, improving training stability. The research also proposes techniques such as selective model upgrade and ensemble pre-trained models to enhance inference capabilities without significantly increasing computational overhead.
Project: https://github.com/groundlight/r1_vlm
demo: https://huggingface.co/spaces/Groundlight/grpo-vlm-decoder
