xAI收購Hotshot,加強AI視頻生成領域佈局
911
中文(繁體)
Groundlight 研究团队近日开源了一套全新的 AI 框架,旨在解决视觉领域中的复杂视觉推理问题,让 AI 不仅能识别图像,还能进行更深层次的推理。当前的视觉语言模型(VLM)在理解图像和结合视觉与文本线索进行逻辑推理时表现不佳。为此,研究团队采用了强化学习方法,并创新性地利用 GRPO(Gradient Ratio Policy Optimization)来提高学习效率。
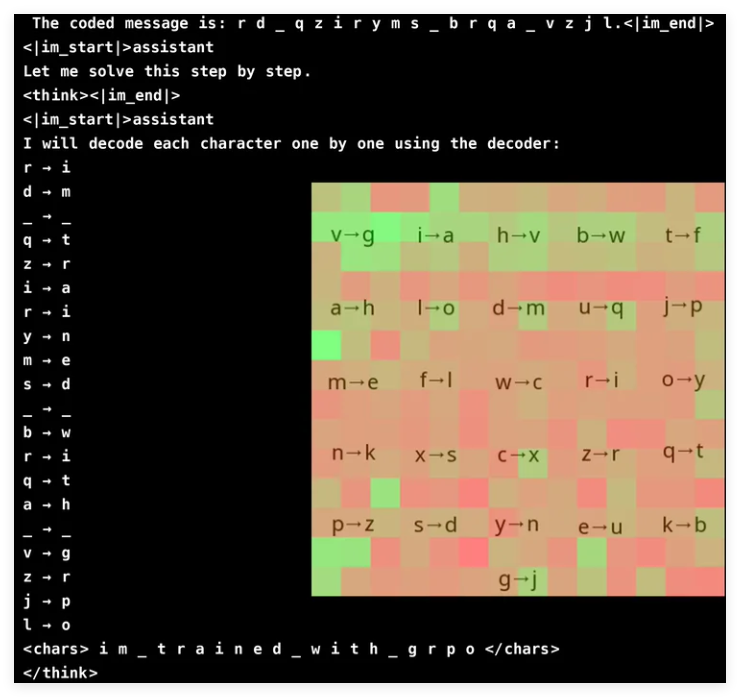
为了验证该方法,研究人员设计了一个密码破译任务,模型需要使用随机生成的解码器图像来解读编码信息。结果显示,一个仅有 30 亿参数的模型达到了 96% 的准确率。GRPO 通过比较多个输出来优化学习过程,提升了训练稳定性。研究还提出了选择性模型升级和集成预训练模型等技术,以在不显著增加计算开销的情况下增强推理能力。
项目:https://github.com/groundlight/r1_vlm
demo:https://huggingface.co/spaces/Groundlight/grpo-vlm-decoder
