The Browser Company launches new AI browser Dia
1003
English
Document conversion has always been a difficult problem in computer science. Traditional methods either rely on complex processes or use multimodal models that consume huge resources. Recently, IBM and Hugging Face teamed up to launch **SmolDocling**, an open source vision-language model (VLM) with only **256M** parameters, designed to solve multimodal document conversion tasks end-to-end.
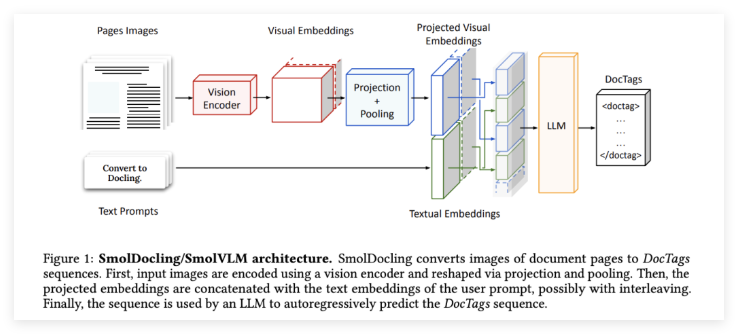
The core advantage of SmolDocling is its compact size and efficient processing capabilities. It accurately captures page elements, structures, and spatial contexts through **DocTags**, a common tag format. Based on the **SmolVLM-256M architecture of Hugging Face, SmolDocling adopts an optimized tokenization and visual feature compression method, significantly reducing computational complexity. It can process the entire document page, taking only 0.35 seconds per page on a consumer GPU, and consumes less than 500MB of video memory.
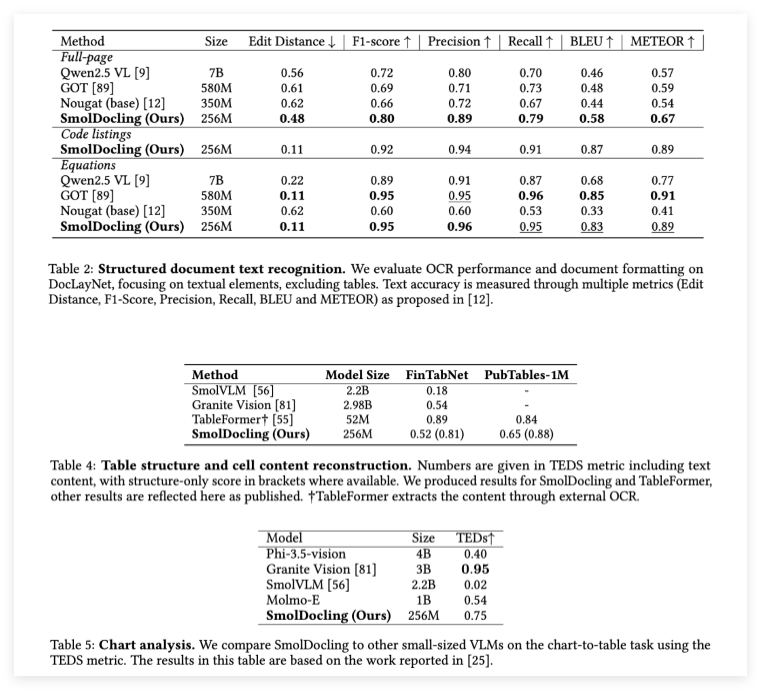
SmolDocling performed well in performance testing. In the full-page document OCR task, it has a significantly higher accuracy than many larger models. SmolDocling has also reached the industry-leading level in formula transcription and code fragment recognition. In addition, it can handle various complex document elements such as code, charts, formulas and documents in different layouts, providing cost-effective solutions for large-scale deployments.
The release of SmolDocling marks a major breakthrough in document conversion technology, demonstrating the potential of compact models in mission-critical tasks. Through innovative training methods and markup formats, SmolDocling sets new standards of efficiency and versatility for OCR technology and provides valuable resources for the community.