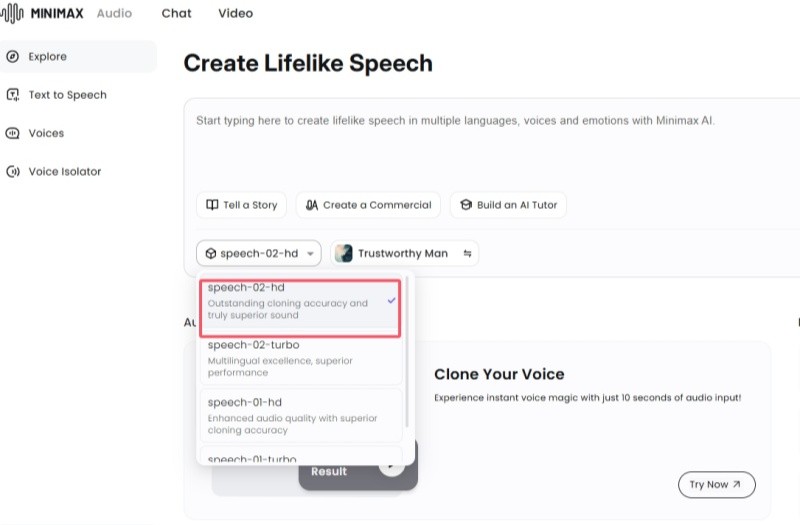
The Browser Company推出全新AI瀏覽器Dia
1019
中文(繁體)
在计算机科学领域,文档转换一直是个难题。传统方法要么依赖复杂流程,要么使用资源消耗巨大的多模态模型。最近,IBM和Hugging Face联手推出了**SmolDocling**,这是一个仅有**256M**参数的开源视觉-语言模型(VLM),旨在端到端地解决多模态文档转换任务。
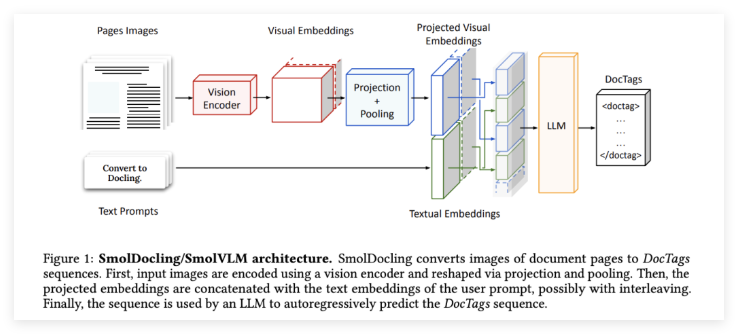
SmolDocling的核心优势在于其小巧的体量和高效的处理能力。它通过**DocTags**,一种通用的标记格式,精确捕捉页面元素、结构和空间上下文。基于Hugging Face的**SmolVLM-256M**架构,SmolDocling采用优化的tokenization和视觉特征压缩方法,显著降低了计算复杂性。它能够处理整个文档页面,在消费级GPU上平均每页仅需0.35秒,且仅消耗不到500MB的显存。
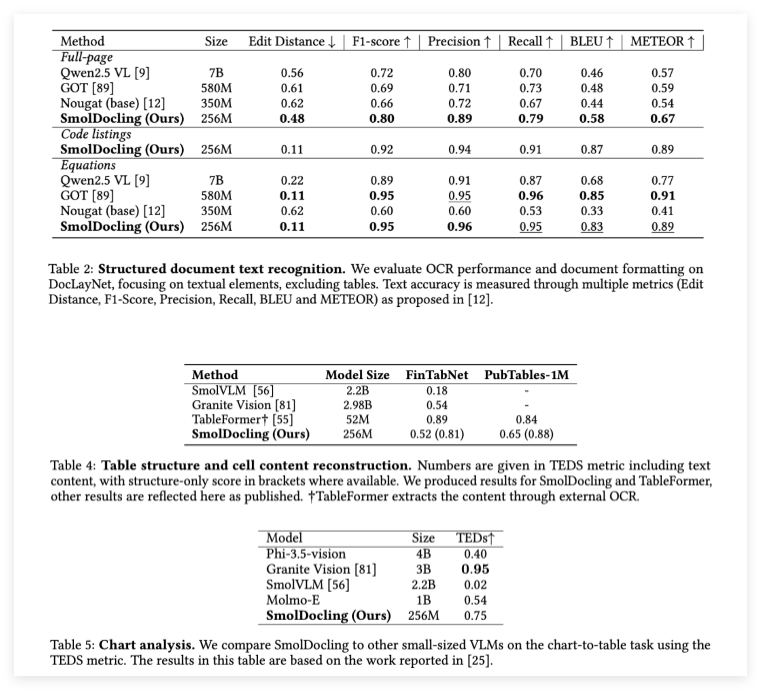
在性能测试中,SmolDocling表现出色。在全页文档OCR任务中,它的准确率显著高于许多体量更大的模型。在公式转录和代码片段识别方面,SmolDocling也达到了行业领先水平。此外,它还能处理各种复杂文档元素,如代码、图表、公式和不同布局的文档,为大规模部署提供了经济高效的解决方案。
SmolDocling的发布标志着文档转换技术的重大突破,展示了紧凑型模型在关键任务中的潜力。通过创新的训练方法和标记格式,SmolDocling为OCR技术树立了新的效率和多功能性标准,并为社区提供了宝贵的资源。