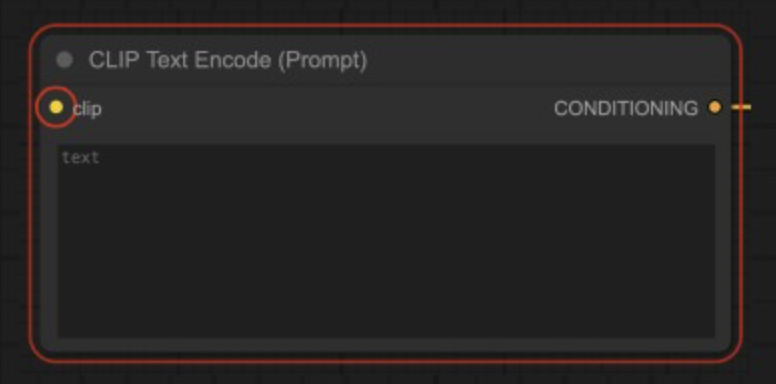
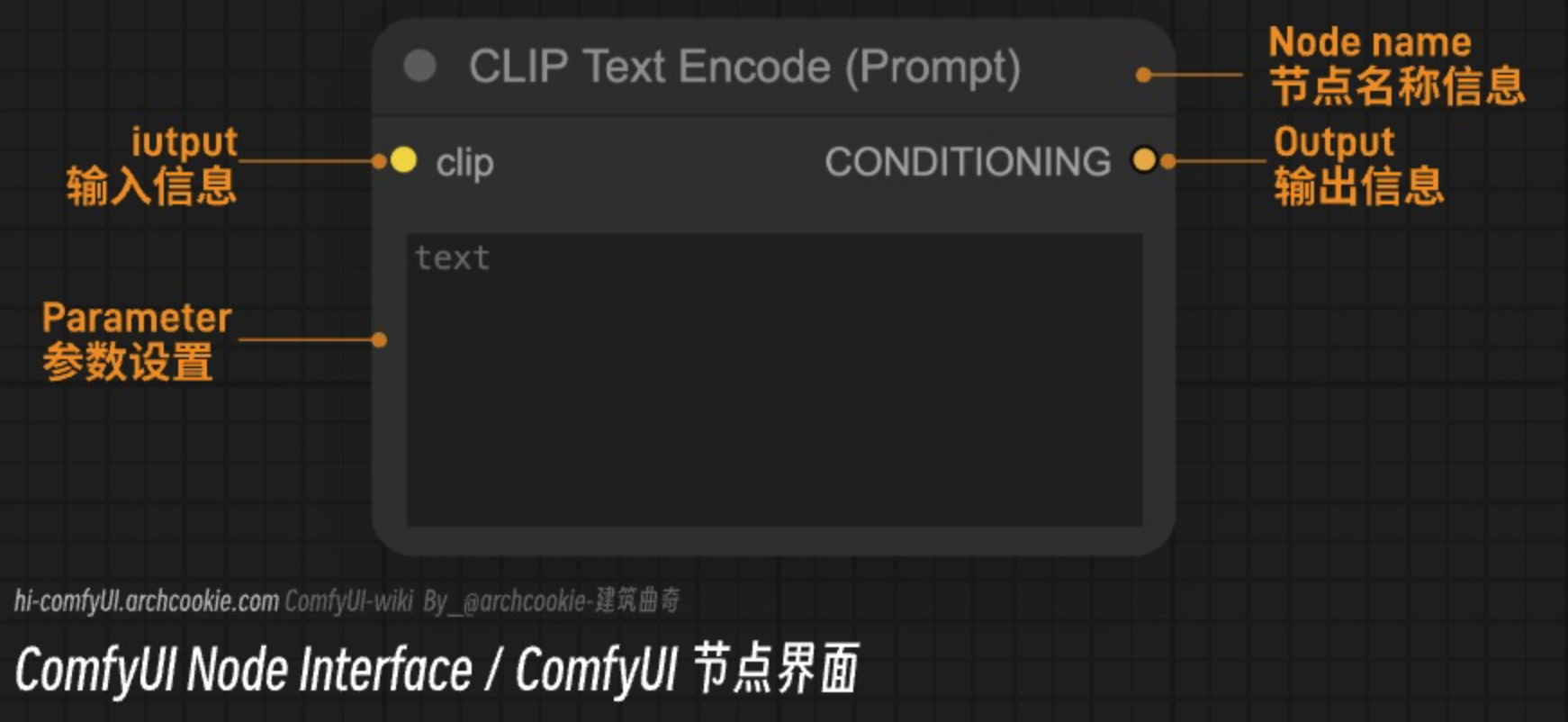
What should I do if the ComfyUI node reports an error? ComfyUI node error solution
1012
English
Recently, Zhejiang University and Alibaba Damo Academy jointly released an eye-catching research aimed at creating high-quality multi-modal textbooks through instructional videos. This innovative research result not only provides new ideas for the training of large-scale language models (VLMs), but may also change the way educational resources are utilized.
With the rapid development of artificial intelligence technology, the pre-training corpus of VLMs mainly relies on image-text data and image-text intertwined corpus. However, most of the current data comes from web pages, the correlation between text and images is weak, and the knowledge density is relatively low, making it unable to effectively support complex visual reasoning.

In order to meet this challenge, the research team decided to extract high-quality knowledge corpus from the large number of teaching videos on the Internet. They collected more than 159,000 teaching videos, and after careful filtering and processing, they finally retained 75,000 high-quality videos, covering multiple subjects such as mathematics, physics, chemistry, etc., with a total duration of more than 22,000 hours.
The researchers designed a complex "video-to-textbook" processing pipeline. First, automatic speech recognition (ASR) technology is used to transcribe the explanation content in the video into text, and then through image analysis and text matching, clips that are highly relevant to the knowledge points are screened out. Finally, these processed keyframes, OCR text, and transcribed text are interleaved and organized to form a multimodal textbook with rich content and rigorous structure.
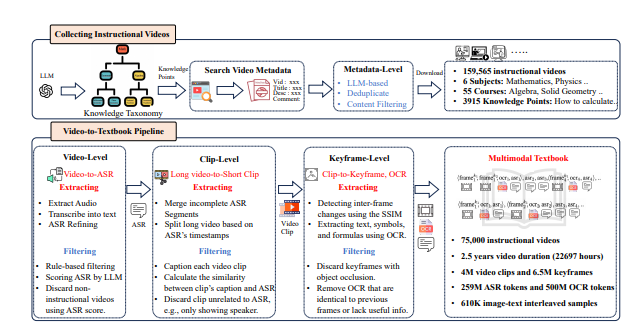
Preliminary results of this study show that compared with previous web-centered data sets, the newly generated textbook data set has significantly improved knowledge density and image correlation, providing a more solid foundation for the learning of VLMs. In addition, the research has attracted widespread attention from the academic community, and the relevant data sets quickly climbed to the top of the popular list on the Hugging Face platform, with more than 7,000 downloads in just two weeks.
Through this innovative attempt, the researchers hope to not only promote the development of VLMs, but also open up new possibilities in the integration and application of educational resources.
Paper address: https://arxiv.org/pdf/2501.00958