Reka AI 發布開源模型Reka Flash 3:21 億參數的通用推理模型
899
中文(繁體)
近日,浙江大學與阿里巴巴達摩院聯合發布了一項引人注目的研究,旨在透過教學影片創建高品質的多模態教科書。這項創新的研究成果不僅為大規模語言模式(VLMs)的訓練提供了新的思路,也可能改變教育資源的運用方式。
隨著人工智慧技術的快速發展,VLMs 的預訓練語料主要依賴圖文對資料與圖文交織語料。然而,目前的這些數據多來自網頁,文字與圖像的關聯性較弱,知識密度也相對較低,無法有效支援複雜的視覺推理。

為了應對這項挑戰,研究團隊決定從網路上海量的教學影片中提煉高品質的知識語料。他們收集了超過15.9萬個教學視頻,經過精細的過濾和處理,最終保留了75,000個高質量視頻,涵蓋數學、物理、化學等多個學科,總時長超過22,000小時。
研究者設計了一條複雜的「視訊到教科書」 處理管道。首先,使用自動語音辨識(ASR)技術將影片中的講解內容轉錄為文本,接著透過圖像分析和文字匹配,篩選出與知識點高度相關的片段。最終,這些處理過的關鍵影格、OCR 文本和轉錄文本被交錯組織,形成了一個內容豐富、結構嚴謹的多模態教科書。
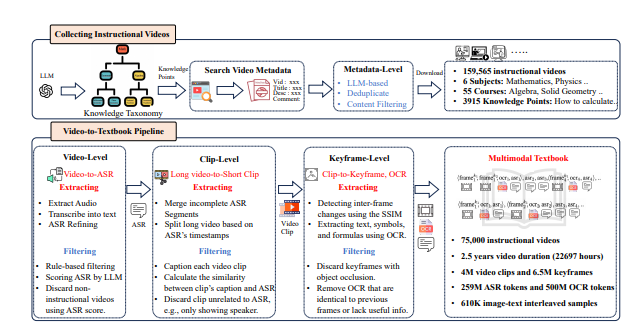
這項研究的初步結果顯示,與以往的網頁中心資料集相比,新生成的教科書資料集在知識密度和圖像關聯性上顯著提升,為VLMs 的學習提供了更為堅實的基礎。此外,研究也引起了學術界的廣泛關注,相關資料集在Hugging Face 平台上迅速攀升至熱門榜單,短短兩週內下載量便超過7000次。
透過這項創新的嘗試,研究者們希望不僅能推動VLMs 的發展,更能在教育資源的整合與應用上開啟新的可能性。
論文網址:https://arxiv.org/pdf/2501.00958