Manus Invitation Code Application Guide
1102
English
In recent years, the advancement of image re-illumination technology has benefited from large-scale data sets and pre-trained diffusion models, making the application of consistent lighting more common. However, in the field of video re-illumination, progress is relatively slow due to the high training cost and the lack of diversified and high-quality video re-illumination datasets.
Just applying the image re-lighting model to video frame by frame will lead to various problems, such as inconsistent light sources and inconsistent appearance of re-lighting, which will eventually lead to flickering in the generated video.
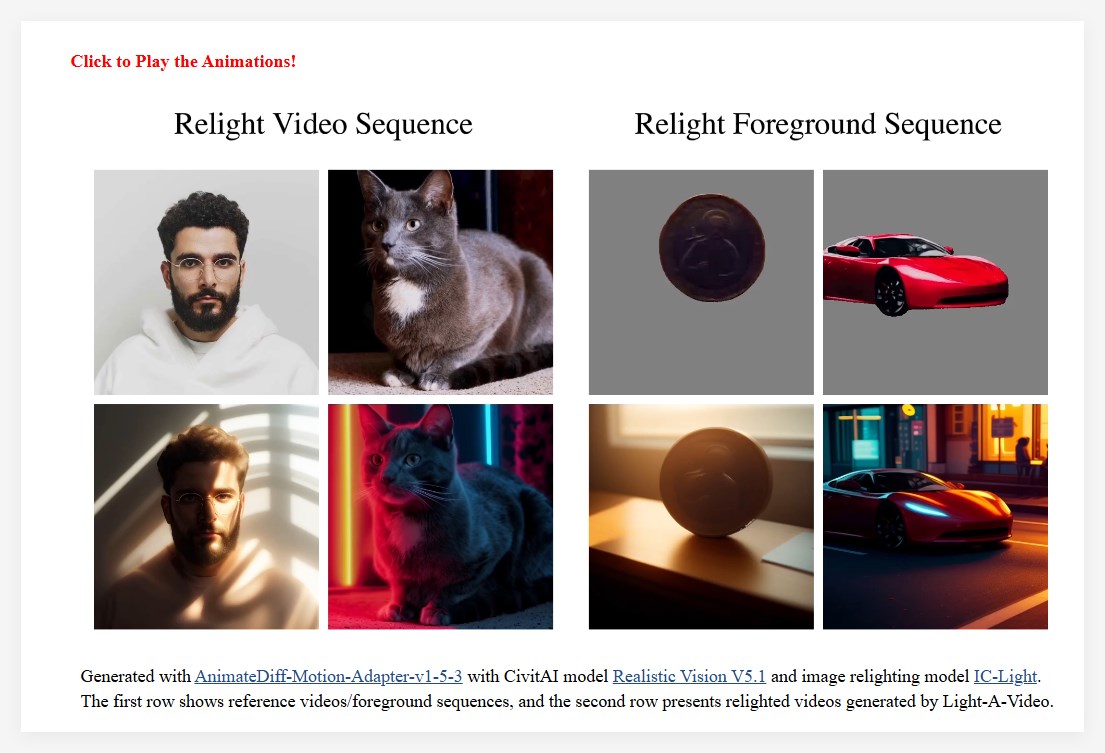
To solve this problem, the research team proposed Light-A-Video, a training-free method that can achieve time-smooth video re-illumination. Light-A-Video borrows the image re-lighting model and introduces two key modules to enhance lighting consistency.
First, the researchers designed a Consistent Light Attention (CLA) module that enhances cross-frame interaction within the self-attention layer to stabilize the generation of background light sources.
Secondly, based on the physical principle of light transmission independence, the research team adopted a linear fusion strategy to mix the appearance of the source video with the appearance of heavy light, and adopted a Progressive Light Fusion (PLF) strategy to ensure smoothness of light in time. transition.
In the experiment, Light-A-Video demonstrated significantly improved the temporal consistency of heavy-light videos while maintaining image quality, ensuring consistency of illumination transitions across frames. The framework shows the processing process of the source video: first, the source video is noise-processed, and then gradually denoised through the VDM model. In each step, the predicted noise-free component represents the denoising direction of the VDM and serves as a consistent target. On this basis, the Consistent Light Attention Module injects unique lighting information to transform it into a heavy lighting target. Finally, the progressive light fusion strategy combines the two goals to form a fusion goal, thus providing a more refined direction for the current steps.
The success of Light-A-Video not only demonstrates the potential of video re-lighting technology, but also points out the direction for future related research.
https://bujiazi.github.io/light-a-video.github.io/








