
Manus邀請碼申請攻略
1105
中文(繁體)
近年來,圖像重光照技術的進步得益於大規模數據集和預訓練的擴散模型,使得一致性光照的應用變得更加普遍。然而,在視頻重光照領域,由於訓練成本高昂以及缺乏多樣化和高質量的視頻重光照數據集,進展相對緩慢。
僅僅將圖像重光照模型逐幀應用於視頻,會導致多種問題,如光源不一致和重光照外觀不一致,最終導致生成的視頻出現閃爍現象。
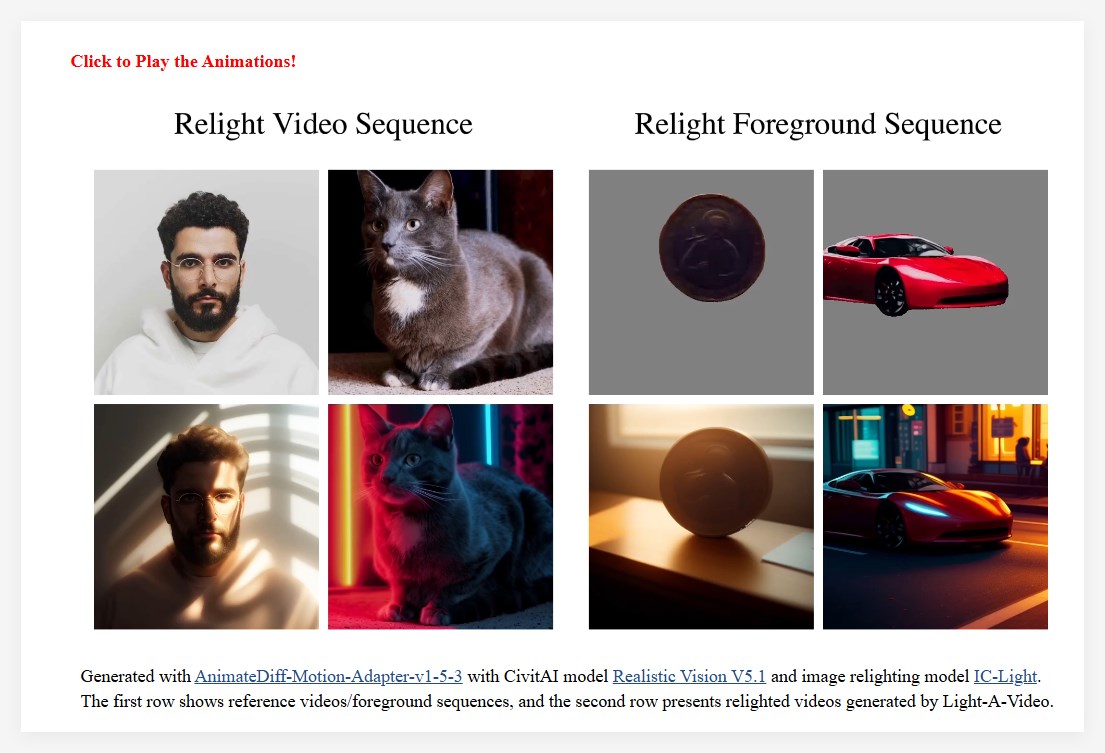
為了解決這一問題,研究團隊提出了Light-A-Video,這是一種無需訓練的、能夠實現時間上平滑視頻重光照的方法。 Light-A-Video 借鑒了圖像重光照模型,並引入了兩個關鍵模塊以增強光照一致性。
首先,研究人員設計了一個一致光注意力(Consistent Light Attention,CLA)模塊,該模塊增強了自註意力層內的跨幀交互,以穩定背景光源的生成。
其次,基於光傳輸獨立性的物理原理,研究團隊採用線性融合策略,將源視頻的外觀與重光照外觀進行混合,採用漸進光融合(Progressive Light Fusion,PLF)策略,確保光照在時間上的平滑過渡。
在實驗中,Light-A-Video 展示了顯著改善重光照視頻的時間一致性,同時保持了圖像質量,確保了跨幀的光照過渡的一致性。框架中展示了源視頻的處理過程:首先對源視頻進行噪聲處理,然後經過VDM 模型進行逐步去噪。在每一步中,預測的無噪聲組件代表了VDM 的去噪方向,並作為一致目標。在此基礎上,一致光注意力模塊注入獨特的光照信息,將其轉變為重光照目標。最後,漸進光融合策略將兩個目標合併,形成融合目標,從而為當前步驟提供了更精細的方向。
Light-A-Video 的成功不僅展示了視頻重光照技術的潛力,也為未來的相關研究指明了方向。
https://bujiazi.github.io/light-a-video.github.io/







