Qventus raises US$105 million to promote AI innovation in the medical industry
382
English
AI image generation technology is developing rapidly, but the model size is getting larger and larger, and the training and use costs are very high for ordinary users. Now, a new text-to-image framework called "Sana" has emerged. It can efficiently generate ultra-high-definition images with resolutions up to 4096×4096, and it is so fast that it can even run on the GPU of a laptop.

Sana's core designs include:
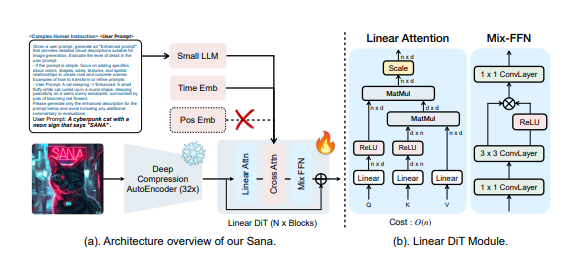
Deep compressive autoencoders: Unlike traditional autoencoders that only compress images 8 times, the autoencoders used by Sana can compress images 32 times, effectively reducing the number of potential tokens. This is crucial for efficient training and generation of ultra-high resolution images.
Linear DiT:Sana replaces all traditional attention mechanisms in DiT with linear attention, which improves the processing efficiency of high-resolution images without sacrificing quality. Linear attention reduces computational complexity from O(N²) to O(N). In addition, Sana also uses Mix-FFN to integrate 3x3 depth convolution into MLP to aggregate local information of tokens and no longer requires position encoding.
Decoder-style text encoder: Sana uses the latest decoder-style small LLM (such as Gemma) as the text encoder, replacing the commonly used CLIP or T5. This approach enhances the model’s ability to understand and reason about user cues, and improves image-text alignment through complex human instructions and contextual learning.
Efficient training and sampling strategy: Sana adopts Flow-DPM-Solver to reduce sampling steps, and uses efficient title annotation and selection methods to accelerate model convergence. The Sana-0.6B model is 20 times smaller and over 100 times faster than large diffusion models such as Flux-12B.
Sana is innovative in that it significantly reduces inference latency by:
Collaborative optimization of algorithms and systems: Through multiple optimization methods, Sana reduces the generation time of 4096x4096 images from 469 seconds to 9.6 seconds, which is 106 times faster than the current most advanced model Flux.
Deep compression autoencoder: Sana uses the AE-F32C32P1 structure to compress images 32 times, significantly reducing the number of tokens and speeding up training and inference.
Linear attention: Using linear attention to replace the traditional self-attention mechanism improves the processing efficiency of high-resolution images.
Triton acceleration: Use Triton to fuse the kernels of the forward and backward processes of the linear attention module to further accelerate training and inference.
Flow-DPM-Solver: Reduces the inference sampling steps from 28-50 steps to 14-20 steps while achieving better generation results.
Sana's performance is outstanding. At 1024x1024 resolution, the parameters of the Sana-0.6B model are only 590 million, but the overall performance reaches 0.64GenEval, which is comparable to many larger models. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU and generates 1024×1024 resolution images in less than 1 second. For 4K image generation, Sana-0.6B achieves throughput more than 100 times faster than the state-of-the-art method (FLUX). Sana not only achieves a breakthrough in speed, but is also competitive in image quality. Even in complex scenes such as text rendering and object details, Sana's performance is satisfactory.
In addition, Sana also has powerful zero-sample language migration capabilities. Even when trained on only English data, Sana can understand Chinese and emoji cues and generate corresponding images.
The emergence of Sana lowers the threshold for high-quality image generation and provides powerful content creation tools for professionals and ordinary users. Sana's code and models will be released publicly.
Experience address: https://nv-sana.mit.edu/
Paper address: https://arxiv.org/pdf/2410.10629
Github:https://github.com/NVlabs/Sana
AI courses are suitable for people who are interested in artificial intelligence technology, including but not limited to students, engineers, data scientists, developers, and professionals in AI technology.
The course content ranges from basic to advanced. Beginners can choose basic courses and gradually go into more complex algorithms and applications.
Learning AI requires a certain mathematical foundation (such as linear algebra, probability theory, calculus, etc.), as well as programming knowledge (Python is the most commonly used programming language).
You will learn the core concepts and technologies in the fields of natural language processing, computer vision, data analysis, and master the use of AI tools and frameworks for practical development.
You can work as a data scientist, machine learning engineer, AI researcher, or apply AI technology to innovate in all walks of life.
