
AnimateDiff A1111 使用教學課程
1008
中文(新加坡)
AI 影像生成技術正在快速發展,但模型體積越來越大,對一般使用者來說,訓練和使用成本都非常高。現在,一種名為「Sana」 的新型文字到影像框架橫空出世,它能夠高效生成高達4096×4096解析度的超高清影像,而且速度驚人,甚至可以在筆記型電腦的GPU 上運行。

Sana 的核心設計包括:
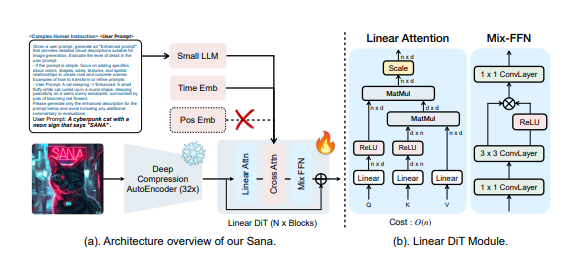
深度壓縮自編碼器:與傳統自編碼器僅壓縮影像8倍不同,Sana 使用的自編碼器可以將影像壓縮32倍,從而有效地減少了潛在的tokens 數量。這對於高效訓練和生成超高解析度影像至關重要。
線性DiT:Sana 以線性注意力取代了DiT 中的所有傳統注意力機制,這在不犧牲品質的前提下,提高了高解析度影像的處理效率。線性注意力將計算複雜度從O(N²) 降低到O(N)。此外,Sana 還採用了Mix-FFN,將3x3深度卷積整合到MLP 中,以聚合tokens 的局部訊息,並且不再需要位置編碼。
解碼器式文字編碼器:Sana 使用了最新的解碼器式小型LLM(如Gemma)作為文字編碼器,取代了以往常用的CLIP 或T5。這種方式增強了模型對使用者提示的理解和推理能力,並透過複雜的人工指令和上下文學習來提高圖像文字的對齊度。
高效的訓練和採樣策略:Sana 採用了Flow-DPM-Solver 來減少採樣步驟,並使用高效的標題標註和選擇方法來加速模型收斂。 Sana-0.6B 模型比大型擴散模型(如Flux-12B)小20倍,速度快100倍以上。
Sana 的創新之處在於,它透過以下方法顯著降低了推理延遲:
演算法和系統的協同優化:透過多種最佳化手段,Sana 將4096x4096影像的生成時間從469秒縮短到9.6秒,比目前最先進的模型Flux 快106倍。
深度壓縮自編碼器:Sana 使用AE-F32C32P1結構,將影像壓縮32倍,顯著減少了tokens 數量,加快了訓練和推理速度。
線性注意力:用線性注意力取代傳統的自註意力機制,提高了高解析度影像的處理效率。
Triton 加速:使用Triton 來融合線性注意力模組的前向和後向過程的內核,進一步加速訓練和推理。
Flow-DPM-Solver:將推理取樣步驟從28-50步減少到14-20步,同時獲得更好的生成效果。
Sana 的性能表現非常出色。在1024x1024解析度下,Sana-0.6B 模型的參數只有5.9億,但整體性能達到了0.64GenEval,與許多更大的型號相比毫不遜色。而且,Sana-0.6B 可以在16GB 筆記型電腦GPU 上部署,產生1024×1024解析度的影像只需不到1秒。對於4K 影像生成,Sana-0.6B 的吞吐量比最先進的方法(FLUX)快100倍以上。 Sana 不僅在速度上取得了突破,在影像品質方面也具有競爭力,即使是複雜的場景,如文字渲染和物件細節,Sana 的表現也令人滿意。
此外,Sana 還具備強大的零樣本語言遷移能力。即使只用英文資料進行訓練,Sana 也能理解中文和表情符號的提示並產生相應的圖像。
Sana 的出現,降低了高品質圖像生成的門檻,為專業人士和普通用戶提供了強大的內容創作工具。 Sana 的程式碼和模型將公開發布。
體驗網址:https://nv-sana.mit.edu/
論文網址:https://arxiv.org/pdf/2410.10629
Github:https://github.com/NVlabs/Sana
AI課程適合對人工智能技術感興趣的人,包括但不限於學生、工程師、數據科學家、開發者以及AI技術的專業人士。
課程內容從基礎到高級不等,初學者可以選擇基礎課程,逐步深入到更複雜的算法和應用。
學習AI需要一定的數學基礎(如線性代數、概率論、微積分等),以及編程知識(Python是最常用的編程語言)。
將學習自然語言處理、計算機視覺、數據分析等領域的核心概念和技術,掌握使用AI工具和框架進行實際開發。
您可以從事數據科學家、機器學習工程師、AI研究員、或者在各行各業應用AI技術進行創新。




