Manus Invitation Code Application Guide
1091
English
Recently, the debate over artificial intelligence benchmarking has become increasingly fierce in the public eye. An OpenAI employee accused Musk of publishing misleading Grok3 benchmark results, while xAI co-founder Igor Babushenjin insisted that the company has no problems.
The cause of the incident was that xAI posted a chart on its blog showing how Grok3 performed in the AIME2025 test. AIME2025 is a collection of challenging math problems in the latest math invitational competition. While some experts doubt the effectiveness of AIME as an AI benchmark, it is still widely used to evaluate the mathematical capabilities of models.
The chart of xAI shows that two variants of Grok3 - Grok3Reasoning Beta and Grok3mini Reasoning surpass OpenAI's current best model o3-mini-high in AIME2025. However, OpenAI employees were quick to point out that the xAI chart did not contain the scores calculated by o3-mini-high on AIME2025 at "cons@64".
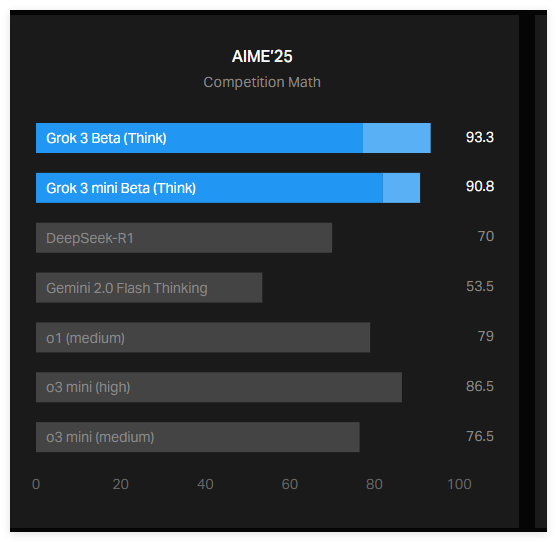
So, what is cons@64? It is the abbreviation of "consensus@64", which simply puts it gives the model 64 chances to try to answer each question and takes the most common answers in the generated answer as the final answer. It can be imagined that the scoring mechanism of cons@64 will significantly improve the baseline score of the model. Therefore, if this data is omitted in the chart, it may make people mistakenly think that one model performs more than another, but this is not the case.
Grok3Reasoning Beta and Grok3mini Reasoning's "@1" score in AIME2025, the score obtained by the model's first attempt, is actually lower than the score of o3-mini-high. Grok3Reasoning Beta's performance is also slightly inferior to OpenAI's o1 model. Despite this, xAI promotes Grok3 as "the smartest AI in the world."
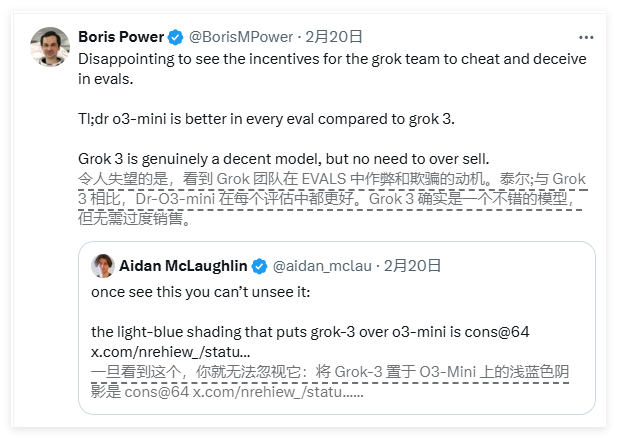
Babushenjin responded on social media that OpenAI has also released similar misleading benchmark charts in the past, mainly comparing the performance of its own models. A neutral expert, however, sorted out the performance of various models into a more "accurate" chart, sparking wider discussion.
Furthermore, AI researcher Nathan Lambert pointed out that a more important indicator remains unclear: the computational (and financial) costs required for each model to achieve the best score. This also shows that the limitations and advantages of the information conveyed by most current AI benchmarks still seem limited to the model.








