Manus Invitation Code Application Guide
1092
English
OpenAI recently released an important AI programming capability assessment report, revealing the current status of AI in the field of software development through a $1 million actual development project. The benchmark, called SWE-Lancer, covers 1,400 real projects from Upwork, comprehensively assesses AI's performance in both direct development and project management.
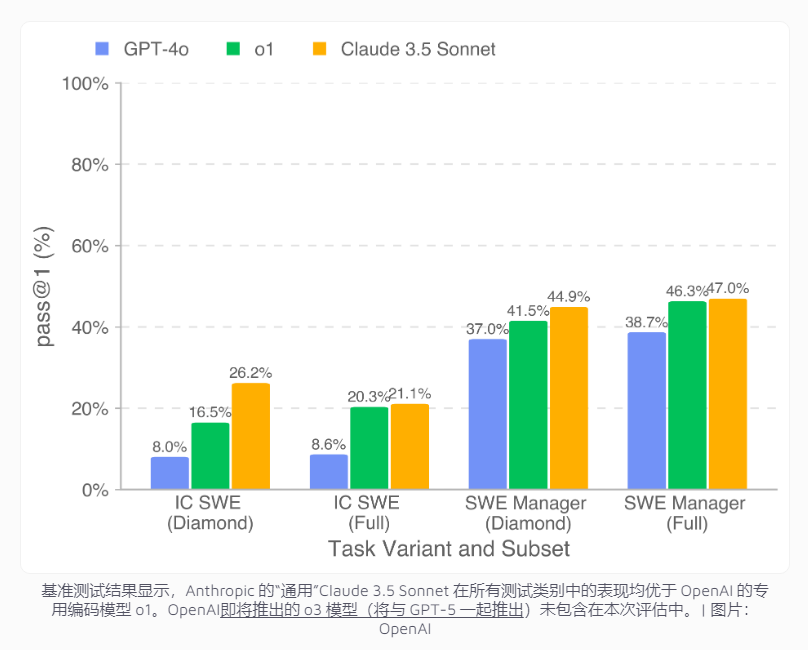
Test results show that the best performing AI model, Claude3.5Sonnet, had a success rate of 26.2% in coding tasks and 44.9% in project management decision-making. Although this achievement is still far from human developers, it has shown considerable potential in terms of economic benefits.
The data shows that the model can complete $208,050 project development work in the public Diamond dataset alone. If extended to a full dataset, AI is expected to handle tasks worth more than $400,000.
However, research also reveals the obvious limitations of AI in complex development tasks. Although AI is competent for simple bug fixes (such as fixing redundant API calls), it performs poorly when facing complex projects that require deep understanding and comprehensive solutions (such as cross-platform video playback feature development). It is particularly noteworthy that AI can often identify problem codes, but it is difficult to understand the root cause and provide comprehensive solutions.
To promote research and development in this field, OpenAI has open sourced the SWE-Lancer Diamond dataset and related tools on GitHub, allowing researchers to evaluate the performance of various programming models based on unified standards. This move will provide an important reference for further improvement of AI programming capabilities.








