
Manus邀請碼申請攻略
1092
中文(繁體)
OpenAI近日發布了一項重要的AI編程能力評估報告,通過價值100萬美元的實際開發項目揭示了AI在軟件開發領域的現狀。這項名為SWE-Lancer的基準測試涵蓋了1,400個來自Upwork的真實項目,全面評估AI在直接開發和項目管理兩大領域的表現。
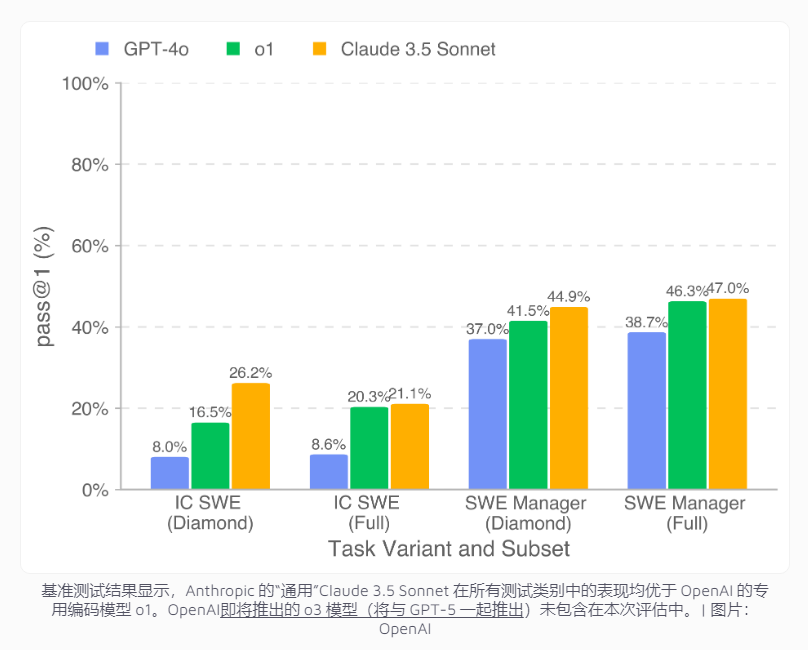
測試結果顯示,表現最佳的AI模型Claude3.5Sonnet在編碼任務中的成功率為26.2%,在項目管理決策方面達到44.9%。雖然這一成績與人類開發者仍有差距,但在經濟效益方面已展現出可觀潛力。
數據顯示,僅在公開的Diamond數據集中,該模型就能完成價值208,050美元的項目開發工作。如果擴展到完整數據集,AI有望處理價值超過40萬美元的任務。
然而,研究也揭示了AI在復雜開發任務中的明顯局限。雖然AI能夠勝任簡單的錯誤修復工作(如修復冗餘API調用),但在面對需要深入理解和全面解決方案的複雜項目時(如跨平台視頻播放功能開發)表現欠佳。特別值得注意的是,AI往往能識別問題代碼,卻難以理解根本原因並提供全面的解決方案。
為推動該領域研究發展,OpenAI已在GitHub上開源了SWE-Lancer Diamond數據集和相關工具,使研究者能夠基於統一標準評估各類編程模型的性能。這一舉措將為AI編程能力的進一步提升提供重要參考。







