Manus Invitation Code Application Guide
1088
English
Voice assistants have gradually become an indispensable part of our lives, while existing digital voice assistants often appear dull and lack emotional and humane elements when interacting with users. In this regard, the Sesame team is working to solve this problem, working to realize a new concept of "voice presence" that allows digital assistants to be more realistic, understood and valued in communication.
Sesame’s core goal is to create a digital companion, not just a tool to process requests, but a partner that can have real conversations. These digital partners hope to gradually build a sense of trust and self-confidence through interaction with users, so that users can experience richer and more profound communication in their daily lives. To this end, the Sesame team focuses on several key components, including emotional intelligence, conversational dynamics, contextual awareness, and consistent personality traits.
Emotional intelligence is the ability to enable voice assistants to understand and respond to users’ emotional states. It not only stays in the understanding of voice commands, but is to be able to perceive emotional changes in the voice and thus make more appropriate feedback. Secondly, dialogue dynamics emphasize the natural rhythm that voice assistants should have during the communication process, including timely pauses, appropriate tone emphasis and interruptions, etc., making the dialogue more smooth and natural.
In addition, context awareness is also crucial. It requires voice assistants to flexibly adjust their tone and style based on the context and history of the conversation to match the current situation. This capability can make digital assistants appear appropriate in different occasions, thereby improving user satisfaction. Finally, consistent personality traits mean that voice assistants should maintain a relatively consistent personality and style in various conversations to enhance users' sense of trust.
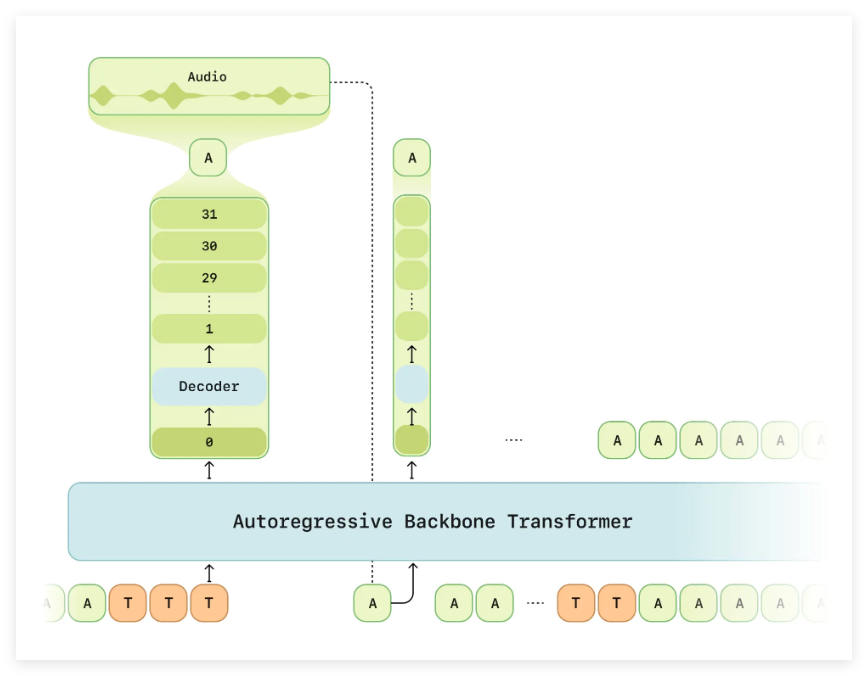
However, it is not easy to achieve the goal of "voice existence". The Sesame team has made progress in various aspects of personality, memory, expressiveness and appropriateness. Recently, the team has demonstrated some experimental results in dialogue speech generation, especially in terms of friendliness and expressiveness, fully demonstrating the potential of its method.
At the technical level, the Sesame team proposed a new approach called the "Dialogue Phonetic Model" (CSM) to address the shortcomings of the traditional text-to-speech (TTS) model. This approach utilizes the converter architecture and aims to achieve more natural and coherent speech generation. CSM not only deals with multimodal learning of text and audio, but also adjusts outputs based on the history of the conversation, thereby solving the shortcomings of traditional models in contextual understanding.
In order to verify the effect of the model, the Sesame team used a large amount of public audio data for training and prepared training samples through transcription, segmentation, etc. They trained models of different sizes and achieved good results on objective and subjective evaluation indicators, and although the model is currently close to human level in terms of naturalness and pronunciation adaptability, it still needs to be improved in specific dialogue situations.
From the samples given by the official, the works generated can hardly hear any AI components, which is super realistic.
The Sesame team plans to open source its research so that the community can participate in experimentation and improvement. This move not only helps accelerate the development of dialogue AI, but also hopes to cover more application scenarios by expanding model scale and language support. In addition, the team plans to explore how to use pre-trained language models to lay the foundation for the construction of multimodal models.
Project demo: https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo








