
Manus邀請碼申請攻略
1088
中文(繁體)
語音助手逐漸成為我們生活中不可或缺的一部分,而現有的數字語音助手在與用戶互動時,往往顯得平淡無奇,缺乏情感和人性化的元素。對此,Sesame 團隊正在努力解決這一問題,致力於實現一種全新的“語音存在” 概念,使得數字助手能夠在交流中更真實、被理解和重視。
Sesame 的核心目標是創造一種數字伴侶,不僅僅是處理請求的工具,而是能夠進行真實對話的伙伴。這些數字伴侶希望通過與用戶的互動,逐步建立信任感和自信心,進而讓用戶在日常生活中體驗到更為豐富和深刻的交流。為此,Sesame 團隊專注於幾個關鍵的組成部分,包括情感智能、對話動態、上下文意識和一致的人格特徵。
情感智能是讓語音助手能夠理解和回應用戶情感狀態的能力。它不僅僅停留在語音命令的理解上,而是要能夠感知語音中的情感變化,從而做出更適當的反饋。其次,對話動態則強調語音助手在交流過程中應具備的自然節奏,包括適時的停頓、恰當的語氣強調和打斷等,使得對話更加流暢和自然。
另外,上下文意識也是至關重要的。它要求語音助手根據對話的背景和歷史,靈活調整語調和風格,以匹配當前的情境。這種能力能夠使得數字助手在不同的場合下都能顯得恰如其分,進而提高用戶的滿意度。最後,一致的人格特徵則意味著語音助手在各類對話中都應保持相對一致的個性和風格,以增強用戶的信任感。
然而,要實現“語音存在” 的目標並非易事。 Sesame 團隊在個性、記憶、表現力和適當性等多個方面的努力取得了逐步進展。近期,團隊展示了一些在對話語音生成方面的實驗成果,特別是在友好性和表現力上進行了優化,充分展現了其方法的潛力。
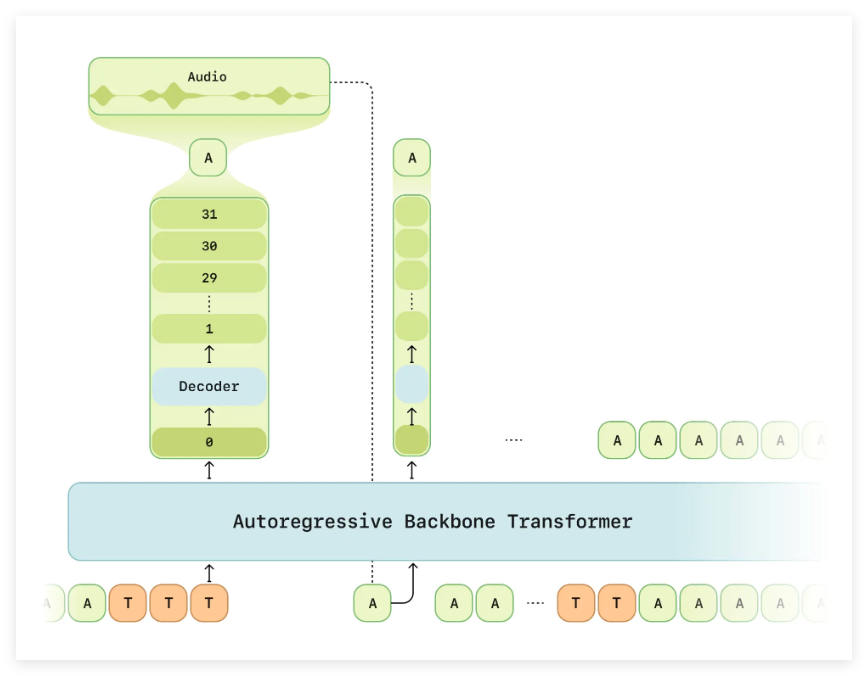
在技術層面,Sesame 團隊針對傳統文本到語音(TTS)模型的不足,提出了一種稱為“對話語音模型”(CSM)的新方法。這種方法利用轉換器架構,旨在實現更為自然和連貫的語音生成。 CSM 不僅處理文本和音頻的多模態學習,還能夠根據對話的歷史來調整輸出,從而解決傳統模型在上下文理解上的短板。
為了驗證模型的效果,Sesame 團隊使用了大量公開的音頻數據進行訓練,並通過轉錄、分段等方式準備訓練樣本。他們訓練了不同規模的模型,並在客觀和主觀評估指標上取得了良好成績,儘管目前模型在自然度和語音適應性方面已接近人類水平,但在具體的對話情境中仍有待提升。
從官方給出的樣本,其生成的作品幾乎聽不出一點AI的成分,超級有真實感。
Sesame 團隊計劃開源其研究成果,以便社區能夠參與實驗和改進。這一舉措不僅有助於加速對話AI 的發展,同時也希望通過擴展模型規模和語言支持,涵蓋更多的應用場景。此外,團隊還計劃探討如何利用預訓練語言模型,為多模態模型的構建奠定基礎。
項目demo:https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice#demo







