Manus Invitation Code Application Guide
1080
English
Today, with the rapid development of technology, artificial intelligence has penetrated into every aspect of our lives. From smart voice assistants to various automation services, AI is changing our lives in an unprecedented way. Today, I want to introduce to you a super cool technology - Spark-TTS, an efficient text-to-speech system based on the Qwen2.5 model. It can not only "clone" your voice, but also "customize" new sounds according to your needs! Doesn't it sound amazing?
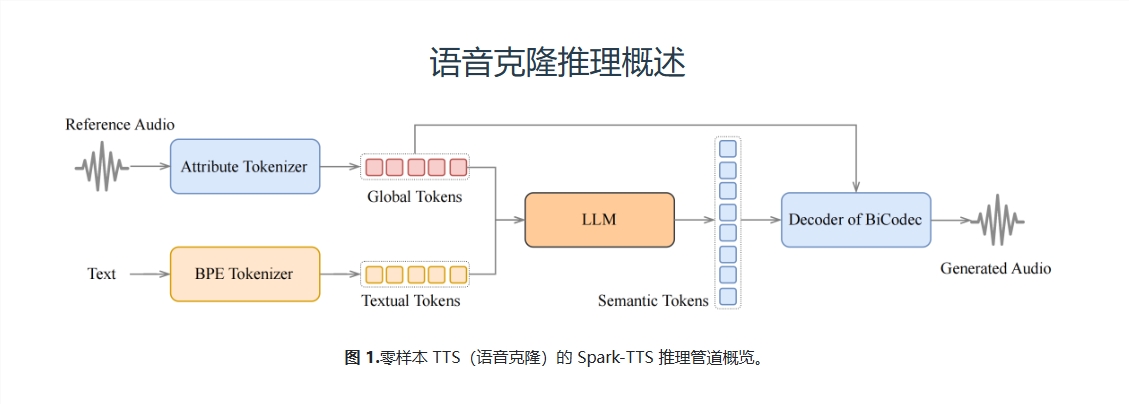
What is Spark-TTS?
Spark-TTS is a new text-to-speech (TTS) system with its core being BiCodec - a single-stream voice codec. This codec can decompose speech into two complementary "voice tokens": one is a semantic token with low bit rate, used to capture language content; the other is a fixed-length global token, used to capture the speaker's attributes, such as tone, tone, etc. This separate representation method combines the powerful Qwen2.5 language model and a generation method called "Thinking Chain" (CoT), allowing Spark-TTS to achieve control from coarse-grained (such as gender, speaking style) to fine-grained (such as precise pitch value, speaking speed). In other words, you can use simple instructions to make Spark-TTS generate a sound that is exactly what you imagined!
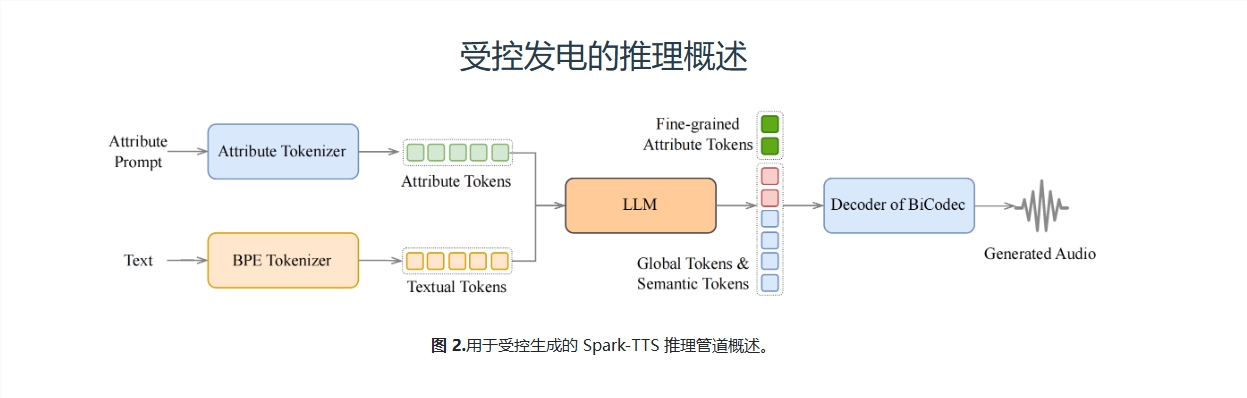
Spark-TTS's "Super Powers"
The great thing about Spark-TTS is its "superpower" - the ability to achieve zero-shot sound cloning. This means that you only need to provide a piece of reference audio, and Spark-TTS can directly generate a brand new sound, and the sound can be adjusted exactly as you want. For example, you can ask to generate a "male, bass, slow" sound, and Spark-TTS can complete the task accurately. This was almost impossible before, but Spark-TTS did it!
In addition, Spark-TTS also has a "secret weapon" - VoxBox. This is a carefully curated open source dataset with 100,000 hours of voice data covering annotations of various attributes such as gender, pitch, and speaking speed. This dataset provides a standardized benchmark for research on speech synthesis, allowing researchers to better conduct experiments and comparisons.
Technical details
The technical details of Spark-TTS may sound a bit complicated, but I will explain it in the most common way. First, BiCodec is the core of Spark-TTS, which converts voice signals into discrete tokens through a technology called "vector quantization" (VQ). These tokens are like "digital fingerprints" of voice, which can be understood and generated by the language model. Then, Spark-TTS uses the powerful capabilities of the Qwen2.5 language model to combine these tokens into a complete speech signal through the "thinking chain" generation method.
In practical applications, Spark-TTS has two working modes: zero sample mode and controllable generation mode. In zero sample mode, Spark-TTS can generate a brand new sound based on the reference audio; and in controllable generation mode, you can create a sound that fully meets your requirements by specifying attribute tags or specific values. For example, you can ask for a "female, high-pitched, fast" sound, and Spark-TTS can complete the task accurately.
Practical application
Spark-TTS has a wide range of application scenarios. For example, in the field of smart voice assistants, Spark-TTS can generate personalized voice based on users' preferences, making users feel like they are communicating with a real person. In the field of audiobooks, Spark-TTS can generate different styles of sounds based on text content, allowing listeners to have a richer auditory experience. In addition, Spark-TTS can also be used in speech synthesis research, helping researchers better understand and improve speech synthesis technology.
Future Outlook
While Spark-TTS has made a big breakthrough, it still has some things to improve. For example, in zero-sample sound clones, the speaker similarity of Spark-TTS needs to be improved. Additionally, Spark-TTS currently does not impose additional constraints on the decoupling between global tokens and semantic tokens, which may affect the diversity and nature of sound. However, researchers are already exploring new ways to solve these problems, such as increasing the diversity and nature of sound by introducing perturbations of tone.
Spark-TTS is a very promising technology that not only enables zero-sample sound cloning, but also generates brand new sounds according to user needs. Its appearance allows us to see the infinite possibilities of speech synthesis technology. In the future, with the continuous advancement of technology, Spark-TTS is expected to be applied in more fields, bringing more convenience and fun to our lives.
Finally, if you are interested in Spark-TTS, you can access its open source code and audio samples and experience this magical technology for yourself. Trust me, it will be a very interesting experience!
Project and demonstration: https://sparkaudio.github.io/spark-tts/
GitHub:https://github.com/SparkAudio/Spark-TTS
Paper: https://arxiv.org/pdf/2503.01710








