
Manus邀請碼申請攻略
1081
中文(繁體)
在科技飛速發展的今天,人工智能已經滲透到我們生活的方方面面,從智能語音助手到各種自動化服務,AI正在以一種前所未有的方式改變我們的生活。今天,我要給大家介紹一項超級酷炫的技術——Spark-TTS,一個基於Qwen2.5模型的高效文本轉語音系統。它不僅能“克隆”你的聲音,還能根據你的需求“定制”出全新的聲音!是不是聽起來很神奇?
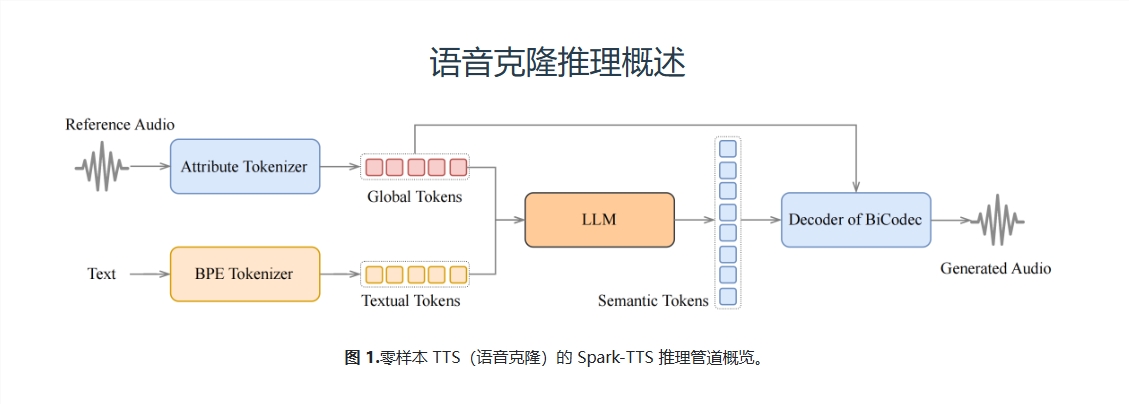
什麼是Spark-TTS?
Spark-TTS是一種新型的文本轉語音(TTS)系統,它的核心是BiCodec——一種單流語音編解碼器。這個編解碼器可以把語音分解成兩種互補的“語音令牌”:一種是低比特率的語義令牌,用來捕捉語言內容;另一種是固定長度的全局令牌,用來捕捉說話者的屬性,比如音色、音調等。這種分離式的表示方法,結合了強大的Qwen2.5語言模型和一種叫做“思維鏈”(CoT)的生成方法,讓Spark-TTS能夠實現從粗粒度(比如性別、說話風格)到細粒度(比如精確的音高值、說話速度)的控制。換句話說,你可以通過簡單的指令,讓Spark-TTS生成一個完全符合你想像的聲音!
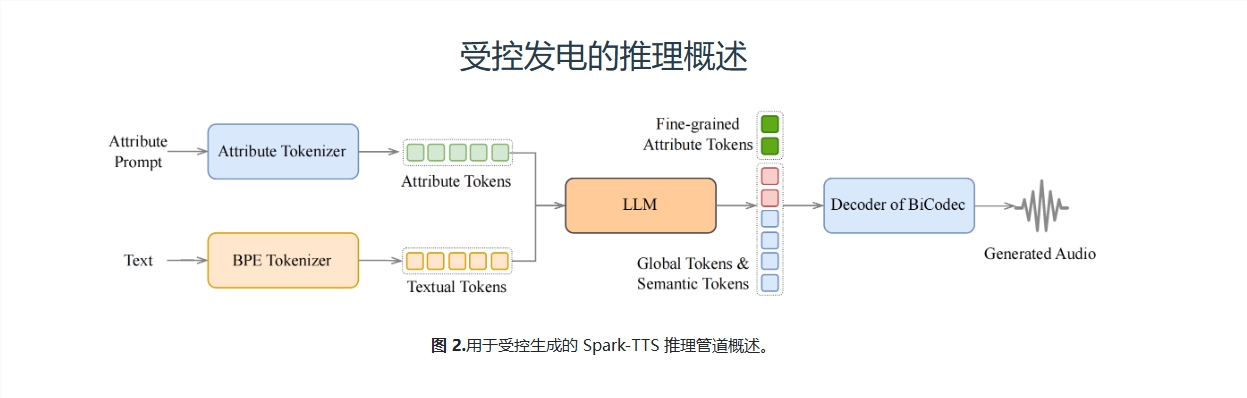
Spark-TTS的“超能力”
Spark-TTS的厲害之處在於它的“超能力”——能夠實現零樣本(zero-shot)的聲音克隆。這意味著,你只需要提供一段參考音頻,Spark-TTS就能直接生成一個全新的聲音,而且這個聲音可以完全按照你的要求進行調整。比如,你可以要求生成一個“男性、低音、慢速”的聲音,Spark-TTS就能精準地完成任務。這在以前幾乎是不可能的,但Spark-TTS做到了!
此外,Spark-TTS還有一個“秘密武器”——VoxBox。這是一個精心策劃的包含10萬小時語音數據的開源數據集,涵蓋了各種屬性的標註,比如性別、音高和說話速度。這個數據集為語音合成的研究提供了一個標準化的基準,讓研究人員可以更好地進行實驗和比較。
技術細節
Spark-TTS的技術細節聽起來可能有點複雜,但我會用最通俗的方式來解釋。首先,BiCodec是Spark-TTS的核心,它通過一種叫做“矢量量化”(VQ)的技術,將語音信號轉換成離散的令牌。這些令牌就像是語音的“數字指紋”,能夠被語言模型理解和生成。然後,Spark-TTS利用Qwen2.5語言模型的強大能力,通過“思維鏈”生成方法,將這些令牌組合成完整的語音信號。
在實際應用中,Spark-TTS有兩種工作模式:零樣本模式和可控生成模式。在零樣本模式下,Spark-TTS可以根據參考音頻生成一個全新的聲音;而在可控生成模式下,你可以通過指定屬性標籤或具體的數值,讓Spark-TTS生成完全符合你要求的聲音。比如,你可以要求生成一個“女性、高音、快速”的聲音,Spark-TTS就能精準地完成任務。
實際應用
Spark-TTS的應用場景非常廣泛。比如,在智能語音助手領域,Spark-TTS可以根據用戶的偏好生成個性化的語音,讓用戶感覺像是在和一個真正的人交流。在有聲讀物領域,Spark-TTS可以根據文本內容生成不同風格的聲音,讓聽眾有更豐富的聽覺體驗。此外,Spark-TTS還可以用於語音合成研究,幫助研究人員更好地理解和改進語音合成技術。
未來展望
雖然Spark-TTS已經取得了很大的突破,但它仍然有一些需要改進的地方。比如,在零樣本聲音克隆中,Spark-TTS的說話者相似度還有待提高。此外,Spark-TTS目前還沒有對全局令牌和語義令牌之間的解耦進行額外的約束,這可能會影響聲音的多樣性和自然度。不過,研究人員已經在探索新的方法來解決這些問題,比如通過引入音色的擾動來提高聲音的多樣性和自然度。
Spark-TTS是一項非常有前景的技術,它不僅能夠實現零樣本的聲音克隆,還能根據用戶的需求生成全新的聲音。它的出現,讓我們看到了語音合成技術的無限可能。未來,隨著技術的不斷進步,Spark-TTS有望在更多的領域得到應用,為我們的生活帶來更多的便利和樂趣。
最後,如果你對Spark-TTS感興趣,可以訪問它的開源代碼和音頻樣本,親自感受一下這項神奇的技術。相信我,這將是一次非常有趣的體驗!
項目及演示:https://sparkaudio.github.io/spark-tts/
GitHub:https://github.com/SparkAudio/Spark-TTS
論文:https://arxiv.org/pdf/2503.01710







